Speculative decoding
Speculative decoding is an inference technique that accelerates the performance of a target model by using a smaller model (the draft model) to speculate the next tokens without affecting the outputs of the target model. SambaStudio allows you to create your own speculative decoding pairs using existing models, as described below, to unlock enhanced performance and efficiency.
|
Speculative decoding is a beta feature of SambaStudio that has been included as an early access feature. |
This document describes:
Speculative decoding process
Speculative decoding is a type of assisted decoding technique meant to accelerate the inference performance of a larger target model by using the generated tokens of a smaller draft model. It works as described in the steps below.
-
A smaller, faster draft model is used to speculate the next set of tokens in a sequence for use by the larger target model.
-
The larger target model is run on the speculated tokens generated by the draft model in parallel.
-
By evaluating each speculated token from the draft model, we use a method called acceptance criteria to accept or reject the speculated tokens.
-
Typically, all good speculative tokens are accepted until a poor speculative token is encountered.
-
When a poor token is encountered, the remaining speculative tokens generated from the draft model are rejected.
-
The above steps are repeated and the draft model generates a new set of speculative tokens starting from the last accepted token. This continues until the response has finished generating.
Acceptance rate
The acceptance rate is the ratio of accepted tokens to total tokens and directly impacts performance.
A high acceptance rate improves inference throughput, or performance. This is because the more generated draft model tokens that are accepted, fewer iterations are required of both models.
Conversely, a low acceptance rate can hurt performance because the target model ends up generating most of the response itself while also incurring the cost of repeatedly calling the draft model. Low acceptance rates often occur if the draft model is not a good representation, or predictor, of the target model. See Choosing a draft model for more information.
When to use speculative decoding
Speculative decoding is ideal for use cases that are performance-sensitive or involve long outputs, as it significantly boosts performance compared to deploying a standalone model. SambaNova provides out-of-the-box speculative decoding pair options that deliver substantial improvements in speed and efficiency.
However, speculative decoding should only be used if the draft model closely aligns with the target model. This is particularly important for fine-tuned or custom checkpoints, as the acceptance rate depends on how well the draft model represents the target model’s token distribution.
For best results, ensure that the draft model is a good predictor of or has been adapted to align with the target model.
When to avoid using speculative decoding
Speculative decoding may not be suitable in the following scenarios, where standard model deployment can be more effective.
-
Long inputs with short outputs.
-
Use cases with long input sequences but short generated outputs can lead to inefficiencies.
-
Example: For a 70B model processing a 16K input, speculative decoding involves running both the draft (e.g., 8B) and target models, resulting in minimal or even negative time savings.
-
-
Large model size difference.
-
A significant size delta between the draft model and target model often results in lower acceptance rates.
-
Lower acceptance rates increase the number of forward passes required, reducing throughput and negating the benefits of speculative decoding.
-
To decide whether speculative decoding is beneficial, consider using performance metrics or calculators to estimate acceptance rates and potential time savings. If the acceptance rate is expected to be low, standard deployment may be more efficient.
View a speculative decoding pair in the Model Hub
You can find a speculative decoding pair model card in Model Hub by selecting Speculative Decoding in the Model Type filters.
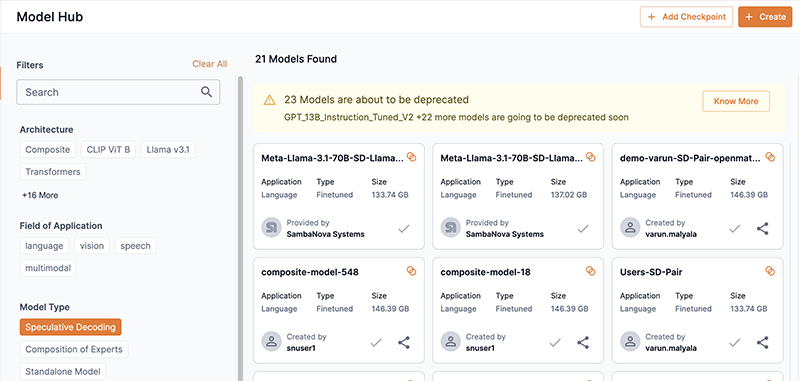
Speculative decoding pairs are indicated by a intersecting circles badge in their previews and model cards.

Create a speculative decoding pair using the GUI
Follow the steps below to create a speculative decoding pair in SambaStudio using the GUI.
|
The % DDR used indicator bar (in the upper right corner) displays the amount of Double Data Rate (DDR) memory used by models during Step 2: Select Target Model and Step 3: Select Draft Model steps. SambaStudio tracks and displays the memory used as a percentage and displays it in real-time updates. 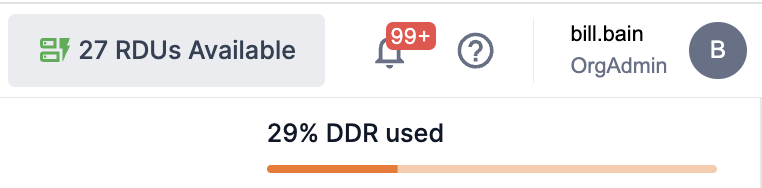
Figure 3. % DDR used indicator bar
|
-
From the Model Hub, click Create in the upper right corner. The Select Model Type box will open.
-
Select Speculative Decoding Pair and click Continue.

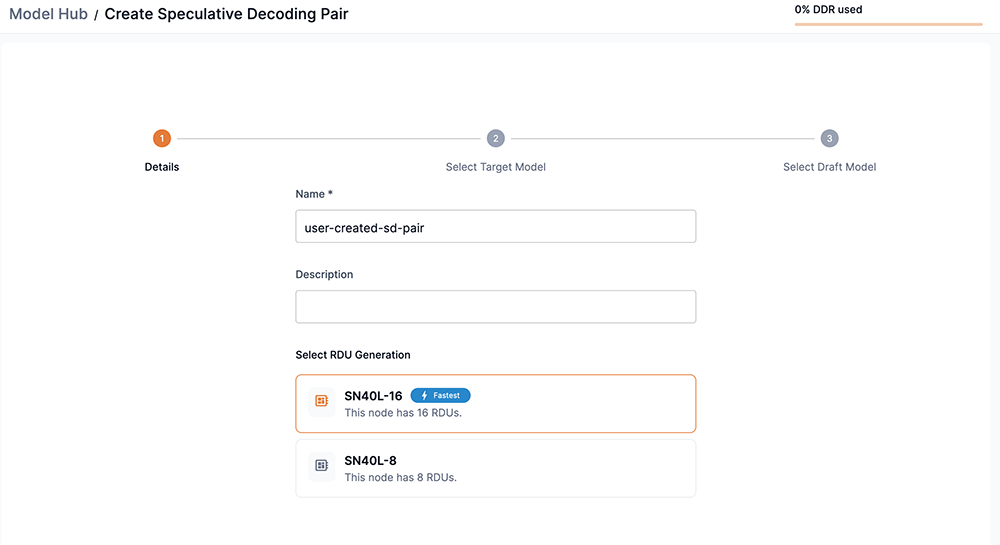
Step 1: Details
-
Enter a name for the speculative decoding pair you are creating in the Name field.
-
Select an RDU generation to use.
-
Click Next to proceed to Step 2: Select Target Model.
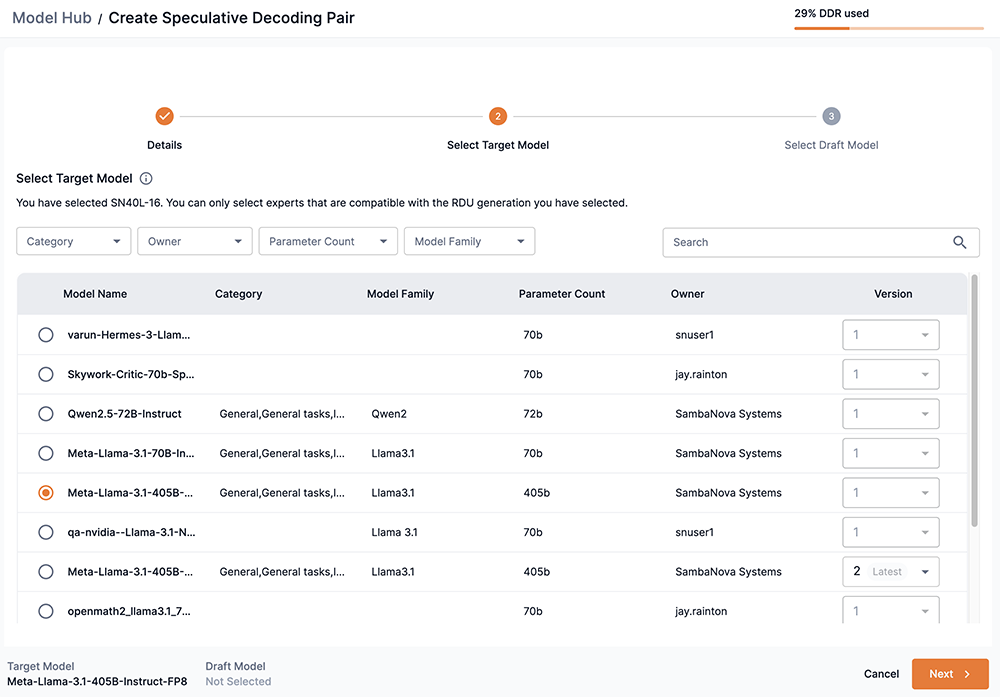
Step 2: Select Target Model
The target model is the model we wish to accelerate by using a smaller and faster draft model to generate the tokens that the target model checks. Using speculative decoding on a target model should yield the same distributions of outputs as if we were using the model by itself. The closer a draft model’s outputs are to the target model, the faster the performance.
|
If you want to use a checkpoint that you have added as a target model, it must display a green check in the Speculative Decoding column during the Add a checkpoint Validation step. |
-
From the table, select an expert to use as the target model. Only experts that are compatible with the RDU generation (SN40L-8, SN40L-16) you selected in the Select Model Type box will be displayed.
-
Speculative decoding is supported for the target models listed, as shown in Figure 6
-
-
Click Next to proceed to Step 3: Select Draft Model.
Step 3: Select Draft Model
A smaller, faster draft model is used to generate tokens for the target model. See Choosing a draft model for more information on how to choose a compatible draft model for your target model.
-
From the table, select an expert to use as a draft model. Only experts that are compatible with the RDU generation (SN40L-8, SN40L-16) you selected in the Select Model Type box will be displayed.
-
Click Run Checks to validate the model.
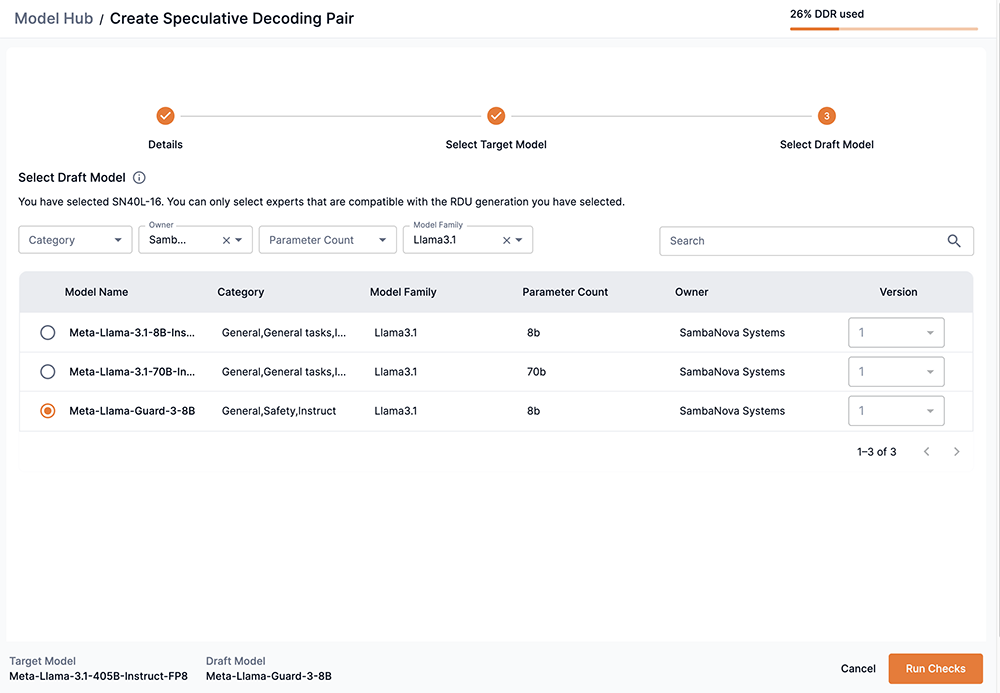
Run checks
The Running Checks box will display while the platform validates your target and draft model choices. This is similar to the Validate step in the CLI.
You can click Cancel to stop the validation.
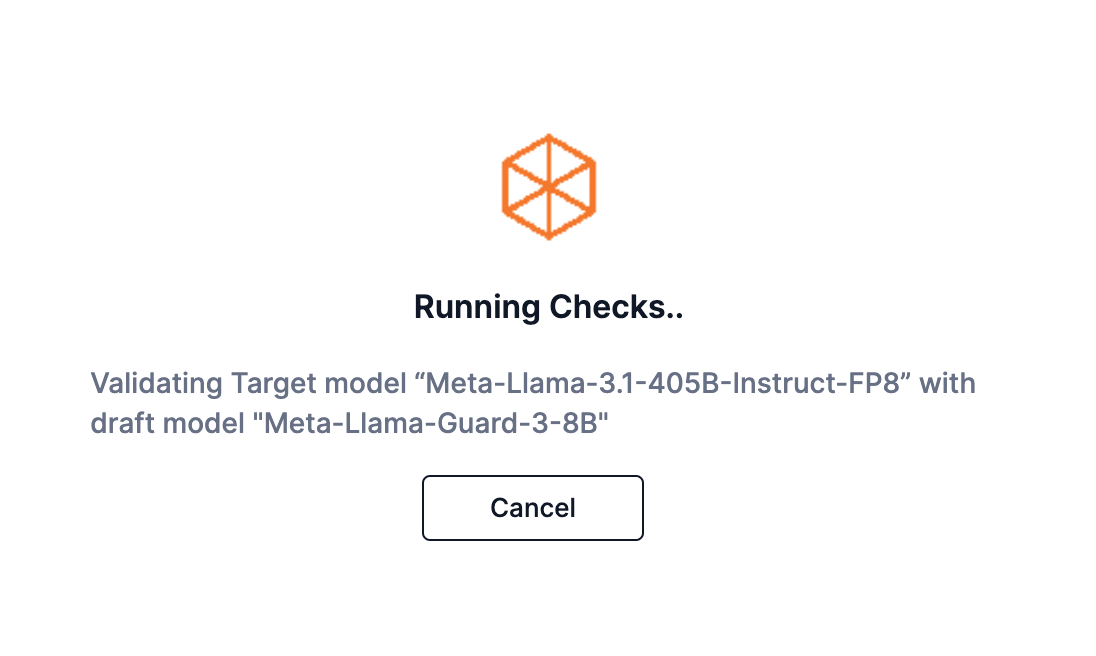
Review details
The Review Details box will display after the validation has completed and no issues have been found.
-
You can change the name and description you entered for your speculative decoding pair.
-
Click Create Pair to complete the process. Your new speculative decoding pair will display in the Model Hub.
Create a speculative decoding pair using the CLI
The example below demonstrates how to create a speculative decoding pair using the CLI.
|
See Choosing a draft model for more information on how to choose a compatible draft model for your target model. |
Validate
First, you should use the snapi model validate-spec-decoding to check if a draft model is compatible for your selected target model. This is similar to the Run checks step in the GUI.
You can specify the following:
-
The name of the target model.
-
The version of the target model, if more than one is available, in the target-version input.
-
The name of the draft model.
-
The version of the draft model, if more than one is available, in the draft-version input.
-
The RDU generation architecture in the rdu-arch input.
$ snapi model validate-spec-decoding \
--target <target-model-name> \
--target-version <target-model-version-number> \
--draft <draft-model-name> \
--draft-version <draft-model-version-number> \
--rdu-arch <rdu-generation-architecture>Create speculative decoding pair
After validation is confirmed, use the snapi model create-sd-pair command to create you speculative decoding pair.
See Choosing a draft model for more information on how to choose a compatible draft model for your target model.
You can specify the following:
-
A name to use for your speculative decoding pair in the name input.
-
The name of the target model.
-
The version of the target model, if more than one is available, in the target-version input.
-
The name of the draft model.
-
The version of the draft model, if more than one is available, in the draft-version input.
-
The RDU generation architecture in the rdu-arch input.
$ snapi model create-sd-pair \
--name <name-of-new-sd-pair> \
--target <target-model-name> \
--target-version <target-model-version-number> \
--draft <draft-model-name> \
--draft-version <draft-model-version-number> \
--rdu-arch <rdu-generation-architecture>Choosing a draft model
Selecting an appropriate draft model is important in optimizing the acceptance rate and therefore performance of the target model. Aspects such as the draft model’s vocabulary, tokenizer, model architecture, and what data it was trained on can affect how similar its outputs are to the target model.
For example, using Meta-Llama-3.1-7B-Instruct as a draft model to accelerate Meta-Llama-3.1-405B-Instruct (the target model) would be a compatible pair. This is because the draft model, Meta-Llama-3.1-7B-Instruct, is in the same model family as Meta-Llama-3.1-405B-Instruct and was trained on similar data and tasks.
Compatibility criteria
Although it is not best practice, a draft model, can have a different tokenizer than the target model; however when when using speculative decoding in SambaStudio, be aware of the following compatibility criteria for choosing a draft model.
-
Ensure that the draft model supports the same maximum sequence length as the target model. Consistent sequence lengths prevent issues with truncated or extended inputs during decoding.
-
Select a draft model with a smaller parameter count than the target model.
-
Verify that the draft model is capable of generating text outputs. Since the draft model’s outputs serve as the input for the target model’s refinement, the ability to produce coherent text is fundamental to the speculative decoding workflow.
-
Verify that the token IDs in the draft model’s tokenizer match up to that of the target model (apart from the special tokens).
-
Verify that tokenizer_class in the draft model’s tokenizer_config.json is the same as the target model’s tokenizer_class.
Best practices
The following are not strict criteria in SambaStudio, but are best practice in choosing a draft model for your target model.
-
Preferably, choose a draft model from the same family or series as the target model. For instance, if you’re using Llama-3.1-405B-Instruct as the target model, a compatible draft model would be Llama-3.1-8B-Instruct. Models from the same family are more likely to be compatible in terms of architecture, tokenizer, and vocabulary, reducing the likelihood of integration issues.
-
If your target model is a fine-tuned version of a model such as Meta-Llama-3.1-405B-Instruct, it would improve performance to fine-tune a model such as Meta-Llama-3.1-7B-Instruct with the same data to use as your draft model. Distilling your fine-tuned version of Meta-Llama-3.1-405B-Instruct to a model of a smaller parameter count to use as a draft model is also an option that could improve performance.
Create an endpoint using a speculative decoding pair
Once you have a created your speculative decoding pair, you can use it to create an endpoint for prediction and Playground use.
|
See Create and use endpoints to learn how to create and deploy an endpoint. |
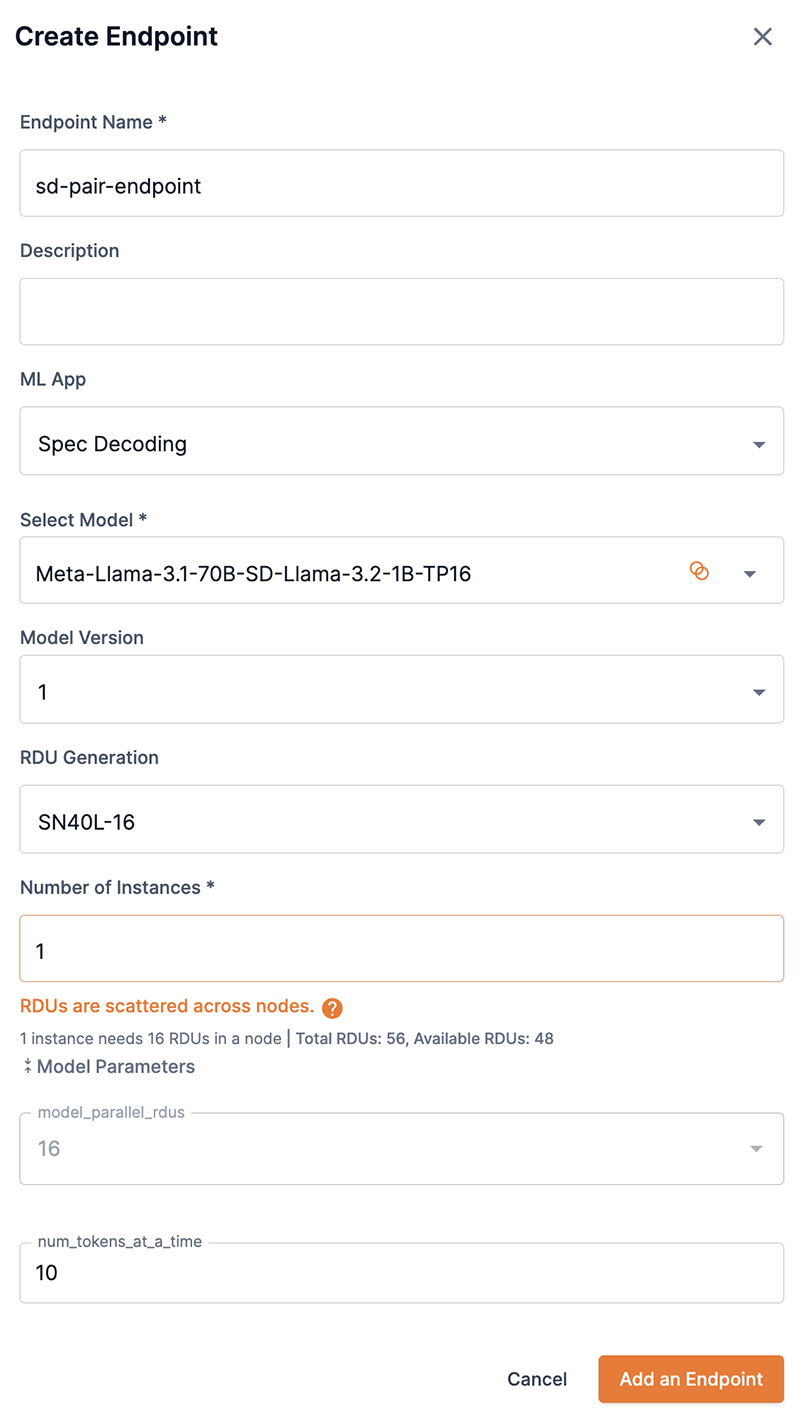
You can deploy an endpoint using a speculative decoding pair by choosing Spec Decoding from the ML App drop-down and the speculative decoding pair name from the Select Model dropdown. Note the intersecting circles badge in the speculative decoding model name.
Create a CoE using a speculative decoding pair
You can create a Composition of Experts (CoE) model that uses a speculative decoding pair as an expert.
|
See Create your own CoE model for more information. |
-
From the Model Hub, click Create CoE Model.
-
In the Create CoE Model box, enter a name for your CoE model into the Name field. Click Continue to proceed.
 Figure 11. Create CoE model box
Figure 11. Create CoE model box -
If your SambaStudio environment is configured with SN40L-8 and SN40L-16, the Select RDU Generation box will open.
-
Select one of the options and click Continue to proceed.
-
-
The Add Experts window will open. The Add Experts window allows you to select and add expert models to your Composition of Experts model.
-
Select Speculative Decoding from the Model Type drop-down filter to display the available speculative decoding models.
-
Select the box next to the speculative decoding expert(s) you wish to add to your CoE model.
-
To view experts other than speculative decoding, use the drop-down filters, Search box, and Expert buttons to refine the displayed list of expert models.
-
Select the box next to the expert(s) you wish to add to your CoE model.
-
-
Click Add Experts to proceed.
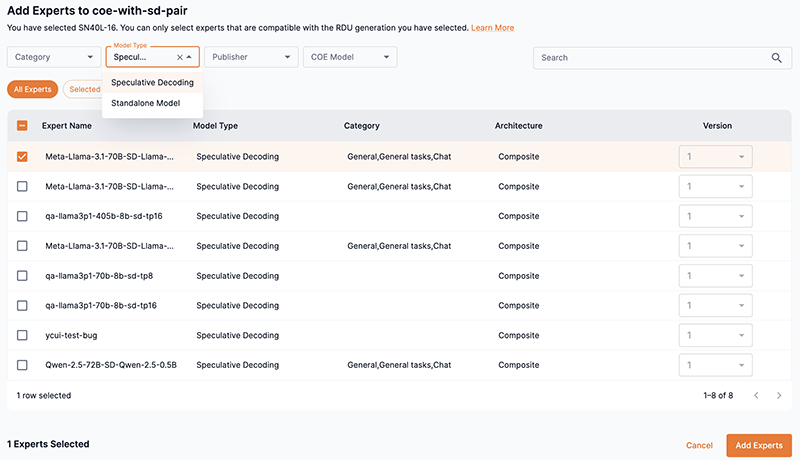 Figure 12. Create CoE Add Experts window
Figure 12. Create CoE Add Experts window -
The Review CoE details box will open. Here you can review and make edits to your CoE Model name or Description.
-
Click Confirm & create CoE to create your new CoE model.
-
Speculative decoding in the Playground
You can use a deployed speculative decoding model in the Playground as an Endpoint or as an Expert of a Composition of Experts (CoE) model.
Speculative decoding endpoint
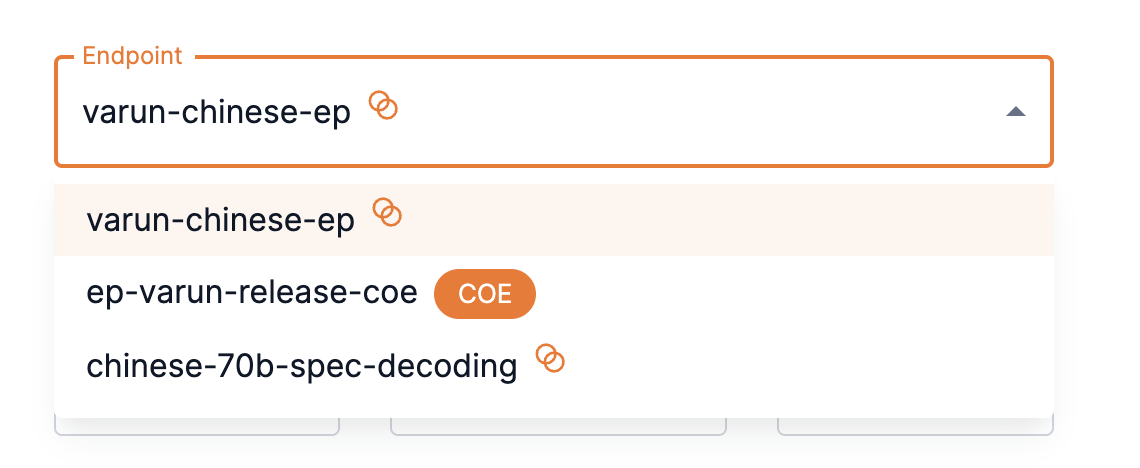
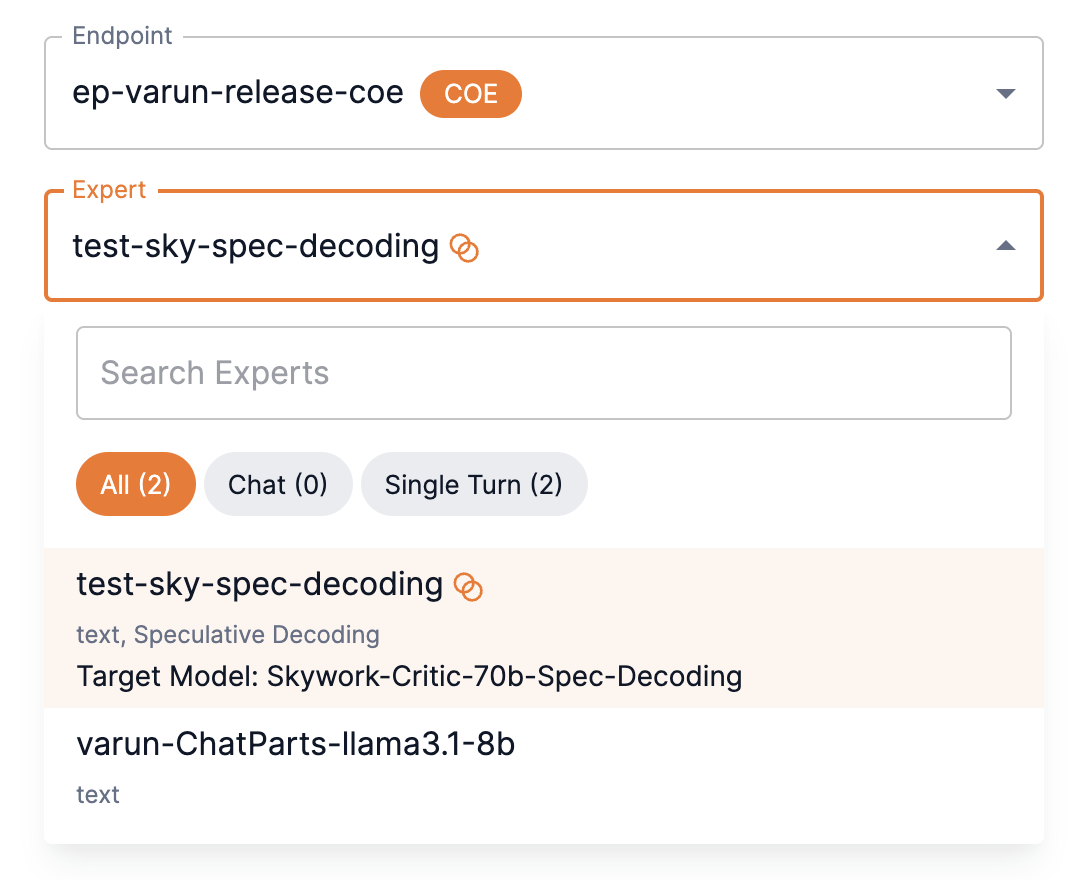
To use a speculative decoding model as an endpoint, select it from the Endpoint drop-down.
Interact with your Speculative decoding endpoint using the CLI
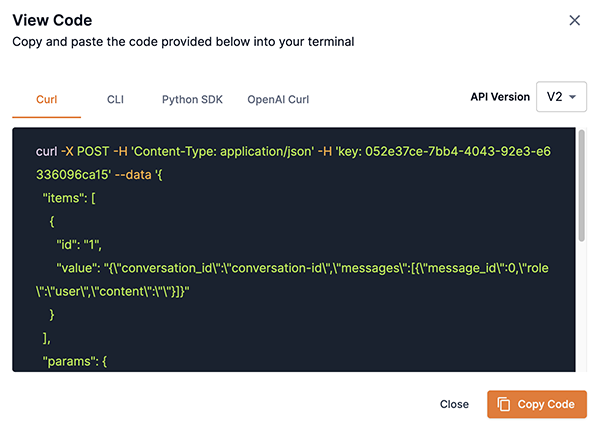
Once your speculative decoding pair has been deployed, you can interact with it as demonstrated in the example curl request below.
curl -X POST -H 'Content-Type: application/json' -H 'key: <your-api-key>' --data '{
"items": [
{
"id": "1",
"value": "{\"conversation_id\":\"conversation-id\",\"messages\":[{\"message_id\":0,\"role\":\"user\",\"content\":\"\"}]}"
}
],
"params": {
"do_sample": false,
"max_tokens_to_generate": 2048,
"process_prompt": true,
"repetition_penalty": 1,
"select_expert": "test-sky-spec-decoding",
"temperature": 1,
"top_k": 50,
"top_p": 1
}
}' '<your-sambastudio-domain>/api/v2/predict/generic/stream/<project-id>/<endpoint-id>'Speculative decoding endpoint usage considerations
Since the Speculative Decoding Model Type is a composition of two models working together, considerations such as how a prompt is constructed, the system prompt, and inference parameters need to be kept in mind to make sure the model that uses speculative decoding behaves as expected.
If process_prompt is specified as False in the inference request, the raw prompt specified in the request body will be applied to both the target model and draft model. This means that the chat template of the draft model will not apply here if process_prompt=False. If process_prompt is set to True, then the default chat template for the target and draft model will be used.
Any inference parameters specified in the parameter menu option in the Playground will be applied to both the target and draft model. Sometimes this means we have to sync the inference parameters of the target and draft models. For instance, if you encounter an error message similar to Got exception running text generation… while running inference on a speculative decoding pair through the playground or API, it is likely because sampling is enabled. The error occurs because either the draft model or the target model does not support sampling. To fix this and sync the target and draft model inference parameters, send a new request with top_k set to 1 and do_sample set to false.