CLIP
CLIP is a multimodal model that understands both images and text. It is trained on diverse image-text pairs, enabling classification without prior knowledge of specific classes. Its visual and text encoders process inputs, producing fixed-size vector representations compared via a contrastive loss function. The resulting multimodal representation proves versatile for various tasks like text and image retrievals, image classification, and object detection, showcasing its broad applicability across visual and textual domains.
Input
An image in any standard format, such as JPEG (Joint Photographic Experts Group) or PNG (Portable Network Graphic), passed to the endpoint as a file. Or, a text string.
Output
The output will be a dictionary containing a data key, with a corresponding value being a list of tensor values that correspond to the embeddings output from the image/text encoder.
{'data': [[-0.024150066077709198, -0.05926524102687836, -0.04773445427417755, -0.01874605007469654, -0.006788679398596287, -0.00362512469291687, 0.010333946906030178, 0.020949017256498337, -0.38842734694480896 ...0.000597264850512147]], 'status_code': 200}Hyperparameters and settings
The hyperparameters and settings for CLIP are described below.
| Parameter | Definition | Allowed values | User Adjustable |
|---|---|---|---|
|
Number of training samples/data points processed together. In this case, it is currently only supported to submit single images/text strings. For a For a |
1, 32 |
Yes |
Deploy a CLIP model
Follow the steps below to deploy an endpoint using CLIP.
-
Create a new project or use an existing one.
-
From a project window, click New endpoint. The Add an endpoint box will open.
-
Select the following settings to create the endpoint:
-
Select CLIP from the ML App drop-down.
-
Select a CLIP model from the Select model drop-down.
-
Expand the Model parameters by clicking the double-blue arrows. From the batch_size drop-down, select either 1 or 32. This will affect how many images/text strings can be sent to the endpoint at once, as described in Hyperparameters and settings above.
-
-
Click Add an endpoint to deploy the endpoint.
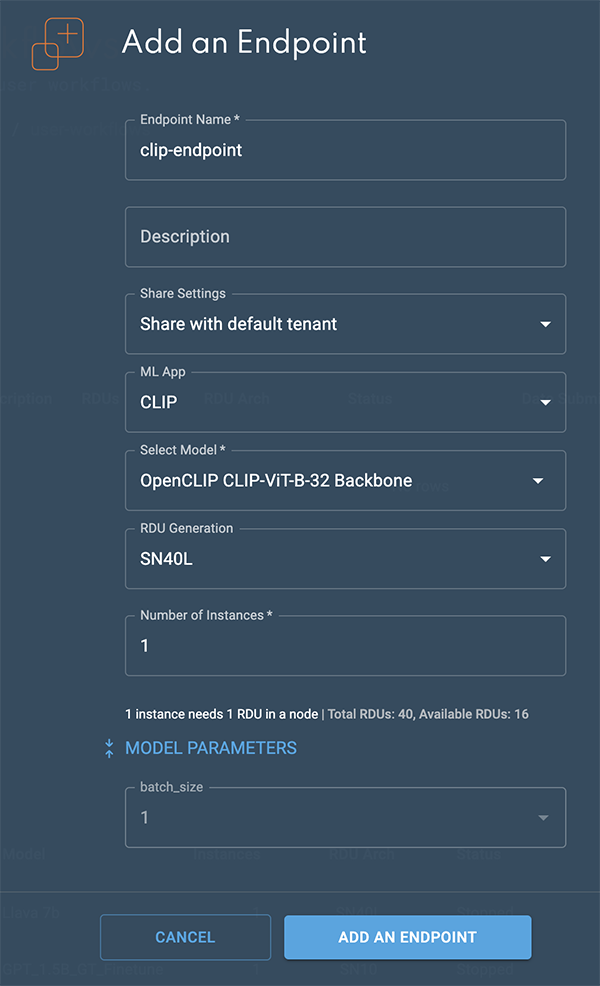 Figure 1. Add an endpoint box
Figure 1. Add an endpoint box -
The Endpoint created confirmation will display.
-
Click View endpoint to open the endpoint details window.
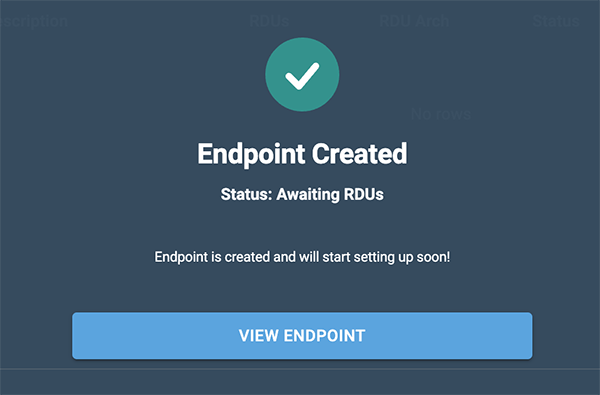 Figure 2. Endpoint confirmation
Figure 2. Endpoint confirmation -
The status will change to Live, after a few minutes, when the endpoint is ready.
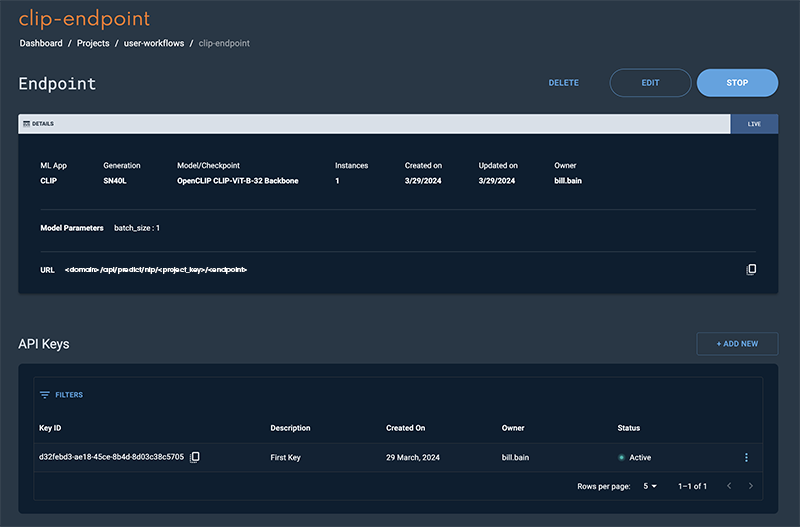 Figure 3. Clip endpoint window
Figure 3. Clip endpoint window
Please refer to the Usage section for instructions on how to interact with the endpoint.
Usage
Once the endpoint has been created in SambaStudio, the following format(s) can be used to interact with the endpoint.
CLIP can take either an image or a text string as the input to generate the corresponding embedding representation as the output. Depending on the modality of the input, you will need to use a slightly different URL path in the CURL cmd.
Batch size 1: Use an image as the input
The example below demonstrates how to pass an image as an input with a batch_size of 1.
|
Only the multipart/form-data format is supported. The ability to pass in an image in the Base64 format as a json payload is not currently supported. |
|
For an image input, be sure the path in your command includes |
curl -X POST \
-H 'key:<your_API_key>' \
--form 'predict_file=@"<PATH_TO_JPG_FILE>"' \
<API address: <domain-address>/api/predict/file/<project-id>/<Endpoint-id>Batch size 1: Use text as the input
The template below demonstrates how to pass text as an input with a batch_size of 1.
|
For a text input, be sure the path in your command includes |
curl -X POST \
-H 'key:<your_API_key>' \
-H 'Content-Type: application/json' \
--data '{"inputs":["Today is a nice day."]}' \
<API address: <domain-address>/api/predict/file/<project-id>/<Endpoint-id>Batch size 32: Use an image as the input
The example below demonstrates sending multiple inputs in a batch. The maximum number of allowable samples is 32, if your endpoint is deployed with a batch_size of 32. The endpoint will automatically do any padding or processing required if the input samples are less than the selected batch size.
|
For predicting on multiple images (up to 32 at a time), you may add additional `--form 'predict_file=@"<PATH_TO_JPG_FILE>"' fields in the request. |
|
For an image input, be sure the path in your command includes |
curl -X POST \
-H 'key:<your_API_key>' \
--form 'predict_file=@"<PATH_TO_JPG_FILE1>"' \
--form 'predict_file=@"<PATH_TO_JPG_FILE2>"' \
<API address: <domain-address>/api/predict/file/<project-id>/<Endpoint-id>Batch size 32: Use text as the input
The template below demonstrates how to pass text as an input with a batch_size of 32.
|
For predicting on multiple strings of text (up to 32 at a time), you can add additional comma-separated strings of text to the list in |
|
For a text input, be sure the path in your command includes |
curl -X POST \
-H 'key:<your_API_key>' \
-H 'Content-Type: application/json' \
--data '{"inputs":["Today is a nice day.", “Hello World”]}' \
<API address: <domain-address>/api/predict/file/<project-id>/<Endpoint-id>Output
Whether using an image or text for the input, the resulting output will be the embedding for the input, as shown below.
{"data": [[0.007865619845688343, 0.1614878624677658, -0.057749394327402115, -0.023593805730342865, -0.027492167428135872, ... 0.00047873161383904517, -0.038996435701847076, -0.002148156752809882, 0.03880875185132027, 0.04024270176887512]]}