E5 Large V2
E5 Large V2 is a general text embedding model that can aid in tasks that require a vector representations such as:
-
Online inference for query embedding generation.
-
Batch inference for document embedding generation.
The output embeddings can then be stored in any vector database of choice, where the retrieval function (based on algorithms such as nearest-neighbor search) will be applied.
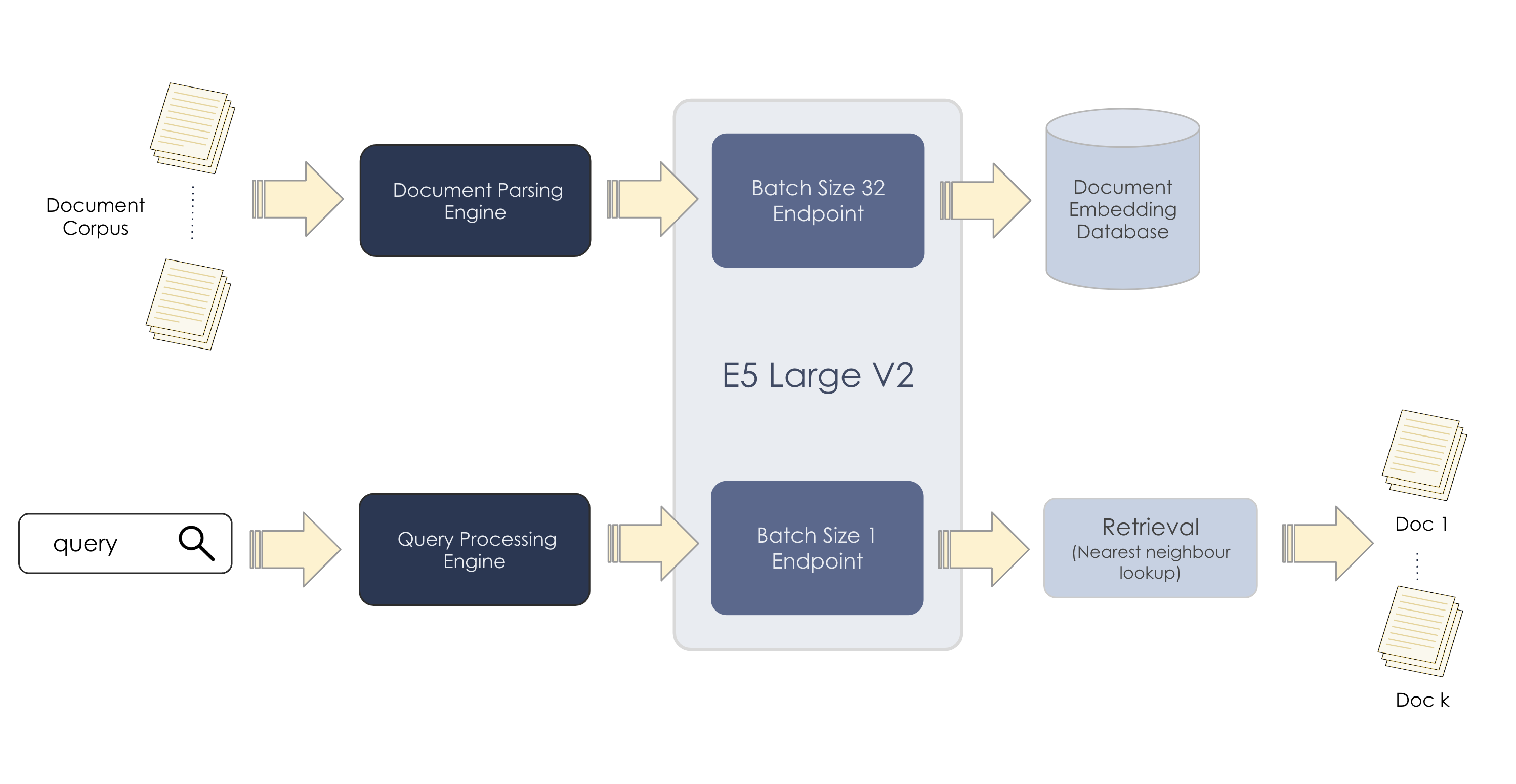
Inference
This section describes how to run inference using the E5 Large V2 model.
Input
When passing a text input into the model, it’s important to adhere to certain conventions to ensure optimal performance. Specifically, adding the prefixes query: and passage: to your input texts can significantly impact the model’s effectiveness. This model only works for English texts. Any long text will be truncated to at most 512 tokens, as that is the sequence length of the model.
|
# Query prefix
["query: input sample 1", "query: input sample 2, ..."]# Passage prefix
["passage: input sample 1", "passage: input sample 2, ..."]Best practices for usage of prefixes:
-
For asymmetric tasks: Use
query:andpassage:prefixes for tasks like passage retrieval in open question answering and ad-hoc information retrieval. -
For symmetric tasks: Employ the
query:prefix for symmetric tasks such as semantic similarity and paraphrase retrieval. -
For embedding-based tasks: Use the
query:prefix when incorporating embeddings as features, such as in linear probing classification and clustering.
"query: How much caffeine is too much caffeine for an adult?""passage: For healthy adults, the FDA has cited 400 milligrams a day—that is about four or five cups of coffee—as an amount not generally associated with dangerous, negative effects"Output
The output will be a raw embedding vector, as shown in the example below.
{"data":[[0.006994775962084532, -0.049408480525016785, 0.008909312076866627, -0.00675021018832922, -0.04235491901636124, 0.03415936231613159, -0.0508863627910614, -0.03758537396788597, -0.03909685090184212, 0.0282646045088768, 0.04117932915687561, -0.04473969340324402, 0.0677141323685646, 0.030095169320702553, -7.
...
...
}The array data in the returned JSON object, when converted to a numpy array will take the shape [<number of samples>, 1024] where 1024 is the embedding size of this model.
|
This may be slightly different from other endpoints whose response will be of shape |
Hyperparameters and settings
The hyperparameters and settings for E5 Large V2 are described below.
| Parameter | Definition | Allowed values | User Adjustable |
|---|---|---|---|
|
Number of samples in a batch. The default in this case is 1. Batch size is set at endpoint creation time. |
Either 1 or 32 |
Yes, at endpoint creation time. |
|
The number of dimensions used to encode the semantic meaning of words or entities in the embedding space. |
1024 |
No |
|
The number of tokens in a sequence that is being processed or encoded into a vector by the embedding model. It represents the length or size of the input sequence for the embedding model. |
512 |
No |
|
If you are vectorizing your knowledge base, using a batch size of 32 would be more suited. If you are serving a live service with 1 user query at a time, a batch size of 1 would be more suited. |
Deploy an E5 Large V2 endpoint
Follow the steps below to deploy an endpoint using E5 Large V2.
|
See Create a non-CoE endpoint using the GUI for detailed information about creating and deploying endpoints. |
-
Create a new project or use an existing one.
-
From a project window, click New endpoint. The Add an endpoint box will open.
-
Select the following settings to create the endpoint:
-
Select TextEmbedding from the ML App drop-down.
-
Select E5 Large V2 from the Select model drop-down.
-
-
Expand the Model parameters by clicking the blue double arrows. This is where the batch size parameter is set.
-
If you are embedding a large amount of documents or text data, using a batch size of 32 is recommended.
-
If you are serving a live service with one user query at a time, a batch size of 1 is recommended.
The batch size can only be set at endpoint creation time. It cannot be passed in as a parameter at inference time.
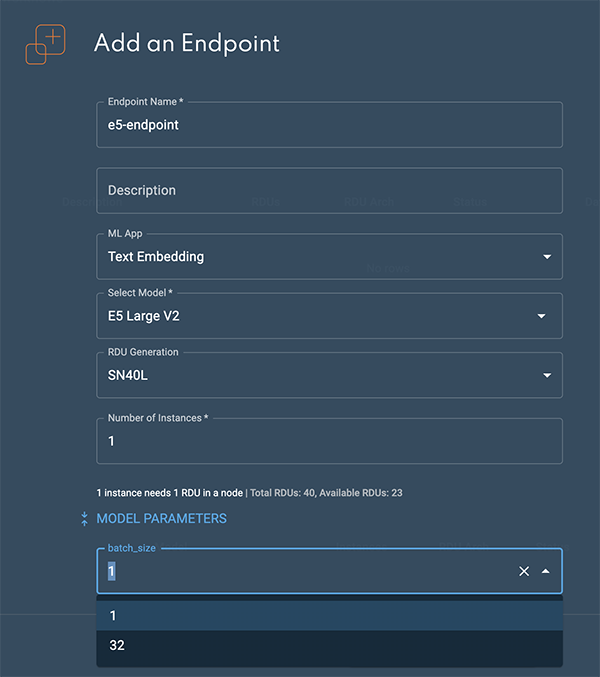 Figure 2. Add an endpoint box
Figure 2. Add an endpoint box
-
-
After selecting the batch size, click Add an endpoint to deploy the endpoint. The Endpoint created confirmation will display.
-
Click View endpoint to open the endpoint details window.
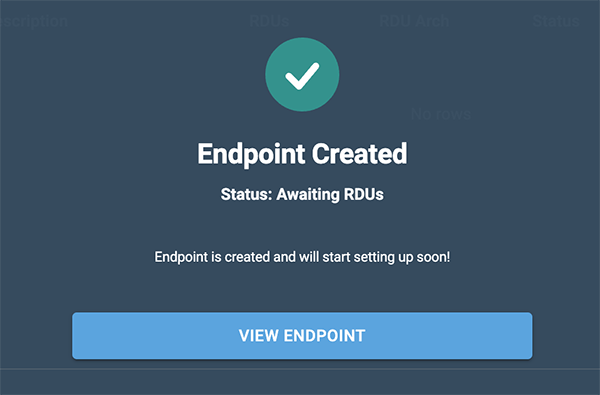 Figure 3. Endpoint confirmation
Figure 3. Endpoint confirmation -
The status will change to Live in a few minutes when the endpoint is ready.
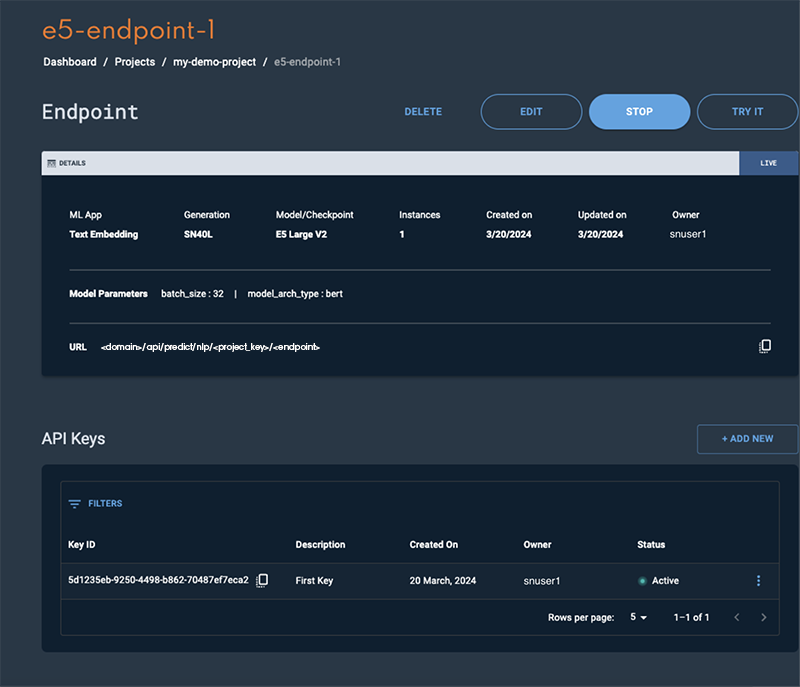 Figure 4. E5 endpoint window
Figure 4. E5 endpoint window
Please refer to the Usage section for instructions on how to interact with the endpoint.
Usage
Once the endpoint has been created in SambaStudio, you can interact with it as described below.
curl -X POST '<your endpoint url>' \
-H 'Content-Type: application/json' \
-H 'key: <your endpoint key>' \
--data '{"inputs":[<list of inputs as strings>]}'The inputs parameter takes in a list of string corresponding to the input samples.
For a batch size of 1, we still pass in a list of one sample.
curl -X POST '<your endpoint url>' \
-H 'Content-Type: application/json' \
-H 'key: <your endpoint key>' \
--data '{"inputs":["query:This is an test of a single sample input"]}'The resulting output will be of shape (1,1024).
The example below demonstrates parallel input. The maximum number of allowable samples is 32, if your endpoint is deployed with a batch_size of 32. The endpoint will automatically do any padding or processing required.
curl -X POST '<your endpoint url>' \
-H 'Content-Type: application/json' \
-H 'key: <your endpoint key>' \
--data '{"inputs":["query: This is a test sample 1", \
"query: This is a test sample 2", \
"query: This is a test sample 3", \
"query: This is a test sample 4"] \
}'The resulting output will be of shape (4,1024).
If we were to pass in more than 32 input samples, we get an error since this exceeds the 32 batch size limit. An example command and error signature is shown below.
curl -X POST '<your endpoint url>' \
-H 'Content-Type: application/json' \
-H 'key: <your endpoint key>' \
--data '{"inputs":["query: This is a test sample 1", \
"query: This is a test sample 2", \
"query: This is a test sample 3", \
...
"query: This is a test sample 32", \
"query: This is a test sample 33"] \
}'Prediction could not be completed for given input due to reason :AppOnlineInferenceFailed message: error running online inference:
Expected a Tensor with batch size <= 32, got batch size: 33Training
This section describes how to prepare data and create a train job using E5 Large V2.
Data preparation
Creating query and passage pairs is essential for training text embeddings. The diversity and quality of these pairs significantly impact the effectiveness of models across different applications. Using the open sourced dataset MS MARCO ![]() as an example, the dataset should be structured into two distinct files: one for passages and another for training data.
as an example, the dataset should be structured into two distinct files: one for passages and another for training data.
Define a directory structure
Define a directory structure to store the training dataset, as described in the example below.
<data_dir>/
passages.jsonl
train.jsonlCreate passages.jsonl
The passages JSONL file (passages.jsonl) contains all of the passages and is the corpus of documents that a query should be matched. The train file (train.jsonl) references the passages.jsonl file. The passage ID numbers that the train.jsonl file reference are the line numbers stored in the passages.jsonl. Be sure to remember which ID number are referenced.
Here is an example passages.jsonl file structure.
{"contents": <str>}Below is a completed example of a passages.jsonl file. In this example, we can see that the first line corresponds to doc_id being 0, the second line being 1, with the pattern continuing.
{"contents":"The presence of communication amid scientific minds was equally important to the success of the Manhattan Project as scientific intellect was. The only cloud hanging over the impressive achievement of the atomic researchers and engineers is what their success truly meant; hundreds of thousands of innocent lives obliterated.}
{"contents":"“Wheat ripens later than barley and, according to the Gezer Manual, was harvested during the sixth agricultural season, yrh qsr wkl (end of April to end of May)” (page 88; also see the chart on page 37 of Borowski’s book, reproduced below)."}
{"contents":"That claim is obviously not correct. God did not hinge the start of a new year on the state of the barley crop, even if on occasions in the first and second centuries A.D. the pharisaical leaders of the Sanhedrin in Jerusalem decided to use the state of the barley harvest to start a new year one new moon later."}
{"contents":"Barley is always sown in the autumn, after the early rains, and the barley harvest, which for any given locality precedes the wheat harvest (Exodus 9:31 f), begins near Jericho in April--or even March--but in the hill country of Palestine is not concluded until the end of May or beginning of June."}Create train.jsonl
The train file (train.jsonl) contains all of the information necessary to run training. The first part of the json object is the "query", which contains the query text. The next two keys are "positives" and "negatives". These keys store the corresponding positive passages and negative passages associated with the "query". The "positives" and "negatives" each point to a dictionary, which contains the key "doc_id". The "doc_ids" refers to the document IDs from the passages.jsonl. For example, if there is a document ID of 128 then it is referring to the 128th line within passages.jsonl. The number of positive documents may vary from 1 → ∞. The upside of having more positive documents is that during each epoch there will be a different positive document associated with the query. The number of negative documents may vary from train_n_passages - 1 → ∞. This is because train_n_passages dictates how many positive + negative passages are associated with a query. Similar benefits to the negative passages the negative passages in that if the number of "doc_id" is greater than train_n_passages - 1, then subsequent epochs will have different variations.
Here is an example of the train.jsonl file structure. Note that train.jsonl should be formatted as one line, but for clarity, we have expanded it in the example structure.
{
"query": <str>,
"positives": {
"doc_id": List[<int, str>]
},
"negatives": {
"doc_id": List[<int, str>]
}
}Below is a completed example of the train.json file.
{"query":")what was the immediate impact of the success of the manhattan project?","positives":{"doc_id":["0"]},"negatives":{"doc_id":["2942565","1668795","3870086","6324845","7249233","3870083","2616684","2395250","2942570","9"]}}
{query":"_________ justice is designed to repair the harm to victim, the community and the offender caused by the offender criminal act. question 19 options:","positives":{"doc_id":["16"]},"negatives":{"doc_id":["7205830","3599633","2280936","8039501","6821173","1641655","2153294","8594243","1411380","5342730"]}}
{"query":"what color is amber urine","positives":{"doc_id":["49"]},"negatives":{"doc_id":["507746","50","4770420","4334506","3855076","217866","8077667","2690484","7653670","1976139"]}}Add your training dataset
After your data is prepared and meets the described requirements, you can add your dataset to SambaStudio using either the GUI or CLI.
-
Follow the steps described in Add a dataset using the GUI to use the GUI.
-
Follow the steps described in Add a dataset using the CLI to use the CLI.
Create an E5 Large V2 train job
Follow the steps described in the Train jobs document to create your E5 Large V2 train job.