Samba-1
Version 1.1
Samba-1 ![]() is SambaNova’s first Composition of Experts implemented model. It allows customers to access many models under a single API endpoint and specify the expert model they want to use for their prompt. This architecture is much more efficient for multi-model deployments.
is SambaNova’s first Composition of Experts implemented model. It allows customers to access many models under a single API endpoint and specify the expert model they want to use for their prompt. This architecture is much more efficient for multi-model deployments.
The 1.3T parameter composition Samba-1 comprises 56 models spanning four distinct model architectures, 10 domains supporting over 30 languages, and a diverse set of tasks. Deploying Samba-1 requires 8 RDUs for a single endpoint, where all 56 models will be loaded into the memory. Samba-1 only runs on SambaNova’s SN40L ![]() .
.
Samba-1 expert models
Samba-1 includes a diverse collection of language and specialized models. Designed to cater to a wide range of use cases, Samba-1 encompasses multilingual chat and content evaluation, as well as domain-specific tasks in coding, finance, law, medicine, and beyond.
Click to view the full list of experts.
The table below describes the expert models available in Samba-1. Expert names with links indicate that the expert uses a task-specific prompt template. Click the link to navigate to the corresponding template.
| Expert Name/ Link to task-specific template |
Base Model | Publisher | Model Overview | Model Description |
|---|---|---|---|---|
Llama2 |
GAIR |
A writing or content judge used to either evaluate other LLMs or human responses |
Auto-J is an open source generative judge that can effectively evaluate different LLMs on how they align to human preference. |
|
BLOOMChatv2-2k |
Bloom |
SambaNova Systems |
176B multilingual chat model developed by SambaNova Systems |
BLOOMChat-v2 is a 176B multilingual chat model developed by SambaNova Systems. It supports conversation, question answering, and generative answers in multiple languages. Fine-tuned from BLOOM on long-sequence multilingual data and assistant-style conversation datasets, it is intended for commercial and research use. However, it should not be used for mission-critical applications, safety-related tasks, or important automated pipelines. |
BLOOMChatv2-8k |
Bloom |
SambaNova Systems |
176B multilingual chat model developed by SambaNova Systems. This model can support more long-form generation and increased input sizes. |
BLOOMChat-v2 is a 176B multilingual chat model developed by SambaNova Systems. It supports conversation, question answering, and generative answers in multiple languages. Fine-tuned from BLOOM on long-sequence multilingual data and assistant-style conversation datasets, it is intended for commercial and research use. However, it should not be used for mission-critical applications, safety-related tasks, or important automated pipelines. |
deepseek-coder-1.3b-instruct |
Llama2 |
Deepseek |
An instruction following coding model that can be instructed using both English and Chinese. This model is optimized for speed/performance relative to its other parameter variants |
DeepSeek Coder is a series of large-scale code language models trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. It provides various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. DeepSeek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks. |
deepseek-coder-33b-instruct |
Llama2 |
Deepseek |
An instruction following coding model that can be instructed using both English and Chinese. This model is optimized for accuracy relative to its other parameter variants |
DeepSeek Coder is a series of large-scale code language models trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. It offers various model sizes ranging from 1B to 33B, each pre-trained on project-level code corpus with a window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling. DeepSeek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks. |
deepseek-coder-6.7b-instruct |
Llama2 |
Deepseek |
An instruction following coding model that can be instructed using both English and Chinese. This model has a balance of speed and accuracy relative to its other parameter variants |
DeepSeek Coder is a series of large-scale code language models trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. It provides various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. DeepSeek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks. |
deepseek-llm-67b-chat |
Llama2 |
Deepseek |
A coding expert that a user can chat with in both English and Chinese with the optimized for the best accuracy compared to its other variants |
DeepSeek LLM is a large language model with 67 billion parameters trained on a 2 trillion token dataset in English and Chinese. It is open-source and available for research purposes. The model can be used for various NLP tasks such as chat completion, text generation, and language understanding. The code repository is licensed under the MIT License, and the use of DeepSeek LLM models is subject to the Model License. |
deepseek-llm-7b-chat |
Llama2 |
Deepseek |
A coding expert that a user can chat with in both English and Chinese with the fastest performance compared to the larger parameter variants |
DeepSeek Coder is a series of large-scale code language models trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. It offers various model sizes ranging from 1B to 33B, each pre-trained on project-level code corpus with a window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling. DeepSeek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks. |
DonutLM-v1 |
Mistral |
cookinai |
A merge of AIDC-ai-business/Marcoroni-7B-v3 and jondurbin/bagel-dpo-7b-v0.1 |
This model is a slerp merge of AIDC-ai-business/Marcoroni-7B-v3 and jondurbin/bagel-dpo-7b-v0.1. It combines the strengths of both models, resulting in improved performance on various tasks. The model is trained with bfloat16 precision and is licensed under the Apache-2.0 license. |
Llama2 |
Wanfq |
An instruction following model used to aid with writing and proofreading tasks |
Explore-Instruct enhances domain-specific instruction coverage by actively exploring the domain space. It employs lookahead and backtracking exploration strategies to generate instruction-tuning data without requiring a predefined tree structure. We release the Explore-Instruct data in brainstorming, rewriting, and math domains on Huggingface Datasets. Each domain includes two versions of datasets: the basic version with 10k instruction-tuning data and the extended version with 16k, 32k, and 64k instruction-tuning data. The data-centric analysis shows that Explore-Instruct effectively covers diverse and fine-grained sub-tasks in each domain. |
|
Falcon-40b-instruct |
Falcon |
tiiuae |
An instruction following model used for tasks such as text classification, sentiment analysis, NER, and data augmentation |
Falcon-40B-Instruct is a 40B parameters causal decoder-only model built by TII based on Falcon-40B and fine-tuned on a mixture of Baize. It is made available under the Apache 2.0 license. Falcon-40B-Instruct is an instruct model, which may not be ideal for further fine-tuning. It features an architecture optimized for inference, with FlashAttention and multiquery. |
finance-chat |
Llama2 |
AdaptLLM |
A helpful chat assistant that can answer finance questions |
We introduce a simple yet effective method to adapt large language models (LLMs) to specific domains. Our method involves transforming large-scale pre-training corpora into reading comprehension texts, which consistently improves prompting performance across tasks in various domains, including biomedicine, finance, and law. Our 7B model outperforms much larger domain-specific models like BloombergGPT-50B. We have released our code, data, and pre-trained models, and are actively working on developing models across different domains, scales, and architectures. |
Llama2 |
GOAT-AI |
A story writing assistant capable of generating captivating content or even narratives/books. |
GOAT-70B-Storytelling, a core model for an autonomous story-writing agent, is introduced by GOAT.AI lab. This model is based on LLaMA 2 70B architecture and trained on a dataset of 18K examples. It generates high-quality, cohesive, and captivating narratives, including stories and books, by utilizing inputs such as plot outlines, character profiles, and their interrelationships. The model is designed specifically for story writers and can be used for generating books, novels, movie scripts, and more. It can be self-hosted via transformers or used with Spaces. The model weights are available under the LLAMA-2 license. However, it’s important to note that the model can produce factually incorrect output and may generate wrong, biased, or offensive content. |
|
law-chat |
Llama2 |
AdaptLLM |
A helpful chat assistant that can answer legal questions |
We introduce a simple yet effective method to adapt large language models (LLMs) to specific domains. Our method involves continued pre-training on domain-specific corpora transformed into reading comprehension texts. This approach consistently improves the prompting performance of LLMs across various tasks in biomedicine, finance, and law domains. Our 7B model even competes with much larger domain-specific models like BloombergGPT-50B. We release our code, data, and pre-trained models to facilitate further research and applications. |
Lil-c3po |
Mistral |
cognAI |
A capable expert that can perform various language tasks. |
lil-c3po is an open-source large language model (LLM) developed by merging two fine-tuned Mistral-7B models. It combines the strengths of both models, featuring Grouped-Query Attention, Sliding-Window Attention, and Byte-fallback BPE tokenizer. The first model, c3-1, is fine-tuned for various language tasks, while the second, c3-2, excels in instructional contexts. Released under the MIT license, lil-c3po is suitable for a wide range of language-related tasks, but may require fine-tuning for specific applications. It should not be used to create hostile or alienating environments. |
llama-2-13b-chat-hf |
Llama2 |
Meta |
A helpful chat assistant with a balance of speed and accuracy |
Meta’s Llama 2 is a collection of pretrained and fine-tuned generative text models ranging from 7 billion to 70 billion parameters. The 13B fine-tuned model, optimized for dialogue use cases and converted for the Hugging Face Transformers format, outperforms open-source chat models on most benchmarks and is on par with popular closed-source models like ChatGPT and PaLM in human evaluations for helpfulness and safety. |
llama-2-13b-hf |
Llama2 |
Meta |
Base llama model with a balance of speed and accuracy |
Meta’s Llama 2 is a collection of pretrained and fine-tuned generative text models ranging from 7B to 70B parameters. The 13B model is available on Hugging Face. Llama-2-Chat models are optimized for dialogue use cases and outperform open-source chat models on most benchmarks. They are on par with closed-source models like ChatGPT and PaLM in human evaluations for helpfulness and safety. |
llama-2-70b-chat-hf |
Llama2 |
Meta |
A helpful chat assistant with high accuracies |
Meta’s Llama 2 is a collection of pretrained and fine-tuned generative text models ranging from 7 billion to 70 billion parameters. The 70B fine-tuned model, optimized for dialogue use cases, is available on Hugging Face. Llama-2-Chat models outperform open-source chat models and are on par with closed-source models like ChatGPT and PaLM in human evaluations for helpfulness and safety. |
llama-2-70b-hf |
Llama2 |
Meta |
Base llama model optimized for accuracy |
Meta’s Llama 2 is a collection of pretrained and fine-tuned generative text models ranging from 7 billion to 70 billion parameters. The 70B model is available on Hugging Face. Llama-2-Chat models are optimized for dialogue use cases and outperform open-source chat models on most benchmarks. The models use an optimized transformer architecture and supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety. |
llama-2-7b-chat-hf |
Llama2 |
Meta |
A helpful chat assistant with the fastest speed/performance compared to the 13B and 70B variants |
Meta’s Llama 2 is a family of large language models ranging from 7B to 70B parameters. The 7B fine-tuned model, optimized for dialogue, is available on Hugging Face. It outperforms open-source chat models and is comparable to closed-source models like ChatGPT and PaLM in human evaluations for helpfulness and safety. The model uses an optimized transformer architecture with supervised fine-tuning and reinforcement learning with human feedback for alignment with human preferences. |
llama-2-7b-hf |
Llama2 |
Meta |
Base llama model designed for speed/performance. |
Meta’s Llama 2 is a collection of pretrained and fine-tuned generative text models ranging from 7B to 70B parameters. The 7B model is available on Hugging Face. Llama-2-Chat models are optimized for dialogue use cases and outperform open-source chat models on most benchmarks. They are on par with closed-source models like ChatGPT and PaLM in human evaluations for helpfulness and safety. |
Llama2 |
Meta |
An expert model great at safety reports and evaluations of text. |
Llama-Guard is a 7B parameter input-output safeguard model based on the recently released Llama 2. It can classify both LLM inputs (prompt classification) and responses (response classification) as safe or unsafe. The model generates text indicating the safety status and, if unsafe, lists the violating subcategories. It is trained on a mix of prompts from the Anthropic dataset and in-house red teaming examples, with ~13K training examples. The model is accompanied by an open taxonomy of harms and risk guidelines. The taxonomy includes categories such as Violence & Hate, Sexual Content, Guns & Illegal Weapons, Regulated or Controlled Substances, Suicide & Self-Harm, and Misinformation. |
|
Llama2 |
ai2lumos |
An agent that can help perform web related tasks by mapping subgoals to web-related actions |
Lumos is a modular language agent with unified formats and open-source LLMs. It consists of planning, grounding, and execution modules built based on LLAMA-2-7B. Trained with ~40K high-quality annotations, Lumos outperforms GPT-4/3.5-based agents on complex QA and web agent tasks, and larger open agents on maths tasks. It also surpasses larger open LLM agents and domain-specific agents on an unseen task, WebShop. This model is a grounding module checkpoint fine-tuned on web agent task in Lumos-Iterative (Lumos-I) formulation. |
|
Llama2 |
ai2lumos |
An agent that can help perform web related tasks by breaking down a single web task into subgoals. |
Introducing Lumos, a suite of complex interactive language agents with unified formats, modular design, and open-source LLMs. Lumos achieves competitive performance with GPT-4/3.5-based and larger open-source agents. It consists of planning, grounding, and execution modules built based on LLAMA-2-7B. Trained with ~40K high-quality annotations, Lumos outperforms GPT-4/3.5-based agents on complex QA and web agent tasks, and larger open agents on maths tasks. It surpasses larger open LLM agents and domain-specific agents on an unseen task, WebShop. |
|
medicine-chat |
Llama2 |
AdaptLLM |
A helpful chat assistant that can answer medical questions |
We introduce a simple yet effective method to adapt large language models (LLMs) to specific domains. Our method involves transforming large-scale pre-training corpora into reading comprehension texts, which consistently improves prompting performance across tasks in various domains, including biomedicine, finance, and law. Our 7B model outperforms much larger domain-specific models like BloombergGPT-50B. We have released our code, data, and models, including 7B and 13B base models and chat models. |
Mistral-7B-Instruct-v0.2 |
Mistral |
Mistral AI |
An instruction following model that can perform general language tasks such as text generation, QA, and summarization |
The Mistral-7B-Instruct-v0.2 is a large language model fine-tuned for instruction following. It is based on the Mistral-7B-v0.1 architecture, which features grouped-query attention, sliding-window attention, and a byte-fallback BPE tokenizer. The model can be used for a variety of tasks, including text generation, question answering, and summarization. To use the model, simply surround your prompt with [INST] and [/INST] tokens. For example, to ask the model for its favorite condiment, you would use the following prompt: [INST] What is your favorite condiment? [/INST]. |
Mistral-T5-7B-v1 |
Mistral |
ignos |
An expert that aims to enhance instructional behavior |
The Mistral model, developed by Ignos, is a fine-tuned version of the Toten5/Marcoroni-neural-chat-7B-v2 model. It aims to enhance instructional behavior and is trained with the QLoRA approach using the tatsu-lab/alpaca dataset. The model is based on the Mistral architecture and trained on RunPod using 3 x RTX 4090 GPUs, 48 vCPU, and 377 GB RAM. It employs Axolotl 0.3.0 and PEFT 0.6.0 frameworks. The model’s bias, risks, and limitations are similar to those of the base models. Huggingface evaluation is pending. |
Llama2 |
Nexusflow |
An expert model great at completing tasks that require the usage of APIs |
Introducing NexusRaven-V2-13B, an open-source function calling LLM surpassing the state-of-the-art. It generates single, nested, and parallel function calls with detailed explanations. NexusRaven-V2 outperforms GPT-4 by 7% in human-generated use cases and generalizes to unseen functions. It’s commercially permissive, trained without proprietary LLMs, and accepts a list of Python functions with arguments and docstrings. Check out our Colab notebook, leaderboard, real-world demo, and GitHub for more info! |
|
Llama2 |
Numbers Station |
A text to SQL generation model optimized for speed/performance. |
NSQL-Llama-2-7B is a large language model fine-tuned for text-to-SQL generation. It is based on Meta’s original Llama-2 7B model and further pre-trained on a dataset of general SQL queries and fine-tuned on text-to-SQL pairs. The model is designed for text-to-SQL generation tasks from given table schema and natural language prompts. It works best with the prompt format defined in the model card and outputting SELECT queries. |
|
Rabbit-7B-DPO-Chat |
Mistral |
viethq188 |
This model can be used to generate responses in the style of a business professional. It can be used for a variety of tasks, such as writing emails, reports, and presentations. |
This model is a merged version of AIDC-ai-business/Marcoroni-7B-v3 and rwitz/go-bruins-v2 using slerp merge. The merge was performed using the mergekit library. After merging, the model was fine-tuned on data from Hugging Face. The model is trained to generate responses in the style of a business professional. It can be used for a variety of tasks, such as writing emails, reports, and presentations. |
Llama2 |
SambaNova Systems |
A text to SQL generation model optimized for accuracy developed by SambaNova Systems and NumbersStation |
SambaCoder-nsql-llama-2-70b is a large language model fine-tuned for text-to-SQL generation. It is based on Meta’s Llama-2 70B model and further pre-trained on a dataset of general SQL queries and fine-tuned on text-to-SQL pairs. The model is designed to generate SQL queries from natural language prompts and works best with the specified prompt format. It is trained to output SELECT queries and can be used for various text-to-SQL generation tasks. |
|
SambaLingo-Arabic-Chat |
Llama2 |
SambaNova Systems |
Bilingual chat assistant |
SambaLingo-Arabic is an English-Arabic bilingual model. SambaLingo is a collection of language expert models trained on llama-2-7b by SambaNova. They achieve state-of-the-art performance on various multilingual benchmarks. The chat versions of the models are human-aligned with DPO. Notably, GPT4-eval consistency favors SambaLingo over other top-tier open source instruction-tuned multilingual models. |
SambaLingo-Bulgarian-Chat |
Llama2 |
SambaNova Systems |
Bilingual chat assistant |
SambaLingo-Bulgarian is an English-Bulgarian bilingual model. SambaLingo is a collection of language expert models trained on llama-2-7b by SambaNova. They achieve state-of-the-art performance on various multilingual benchmarks. The chat versions of the models are human-aligned with DPO. Notably, GPT4-eval consistency favors SambaLingo over other top-tier open source instruction-tuned multilingual models. |
SambaLingo-Hungarian-Chat |
Llama2 |
SambaNova Systems |
Bilingual chat assistant |
SambaLingo-Hungarian is an English-Hungarian bilingual model. SambaLingo is a collection of language expert models trained on llama-2-7b by SambaNova. They achieve state-of-the-art performance on various multilingual benchmarks. The chat versions of the models are human-aligned with DPO. Notably, GPT4-eval consistency favors SambaLingo over other top-tier open source instruction-tuned multilingual models. |
SambaLingo-Japanese-Chat |
Llama2 |
SambaNova Systems |
Bilingual chat assistant |
SambaLingo-Japanese is an English-Japanese bilingual model. SambaLingo is a collection of language expert models trained on llama-2-7b by SambaNova. They achieve state-of-the-art performance on various multilingual benchmarks. The chat versions of the models are human-aligned with DPO. Notably, GPT4-eval consistency favors SambaLingo over other top-tier open source instruction-tuned multilingual models. |
SambaLingo-Russian-Chat |
Llama2 |
SambaNova Systems |
Bilingual chat assistant |
SambaLingo-Russian is an English-Russian bilingual model. SambaLingo is a collection of language expert models trained on llama-2-7b by SambaNova. They achieve state-of-the-art performance on various multilingual benchmarks. The chat versions of the models are human-aligned with DPO. Notably, GPT4-eval consistency favors SambaLingo over other top-tier open source instruction-tuned multilingual models. |
SambaLingo-Serbian-Chat |
Llama2 |
SambaNova Systems |
Bilingual chat assistant |
SambaLingo-Serbian is an English-Serbian bilingual model. SambaLingo is a collection of language expert models trained on llama-2-7b by SambaNova. They achieve state-of-the-art performance on various multilingual benchmarks. The chat versions of the models are human-aligned with DPO. Notably, GPT4-eval consistency favors SambaLingo over other top-tier open source instruction-tuned multilingual models. |
SambaLingo-Slovenian-Chat |
Llama2 |
SambaNova Systems |
Bilingual chat assistant |
SambaLingo-Slovenian is an English-Slovenian bilingual model. SambaLingo is a collection of language expert models trained on llama-2-7b by SambaNova. They achieve state-of-the-art performance on various multilingual benchmarks. The chat versions of the models are human-aligned with DPO. Notably, GPT4-eval consistency favors SambaLingo over other top-tier open source instruction-tuned multilingual models. |
SambaLingo-Thai-Chat |
Llama2 |
SambaNova Systems |
Bilingual chat assistant |
SambaLingo-Thai is an English-Thai bilingual model. SambaLingo is a collection of language expert models trained on llama-2-7b by SambaNova. They achieve state-of-the-art performance on various multilingual benchmarks. The chat versions of the models are human-aligned with DPO. Notably, GPT4-eval consistency favors SambaLingo over other top-tier open source instruction-tuned multilingual models. |
SambaLingo-Turkish-Chat |
Llama2 |
SambaNova Systems |
Bilingual chat assistant |
SambaLingo-Turkish is an English-Turkish bilingual model. SambaLingo is a collection of language expert models trained on llama-2-7b by SambaNova. They achieve state-of-the-art performance on various multilingual benchmarks. The chat versions of the models are human-aligned with DPO. Notably, GPT4-eval consistency favors SambaLingo over other top-tier open source instruction-tuned multilingual models. |
Snorkel-Mistral-PairRM-DPO |
Mistral |
Snorkel AI |
A powerful chat assistant tuned to human preferences |
Our Snorkel-Mistral-PairRM-DPO model is designed for chat purposes and is optimized to provide high-quality responses. It is trained using a unique methodology involving prompt generation, response reranking, and Direct Preference Optimization (DPO). The model is based on the Mistral-7B-Instruct-v0.2 LLM and leverages the PairRM model for response ranking. We believe that specialization is crucial for enterprise use cases, and our approach simplifies the model-building process by focusing on ranking/scoring models rather than extensive manual annotation. This model demonstrates our general approach to alignment, and for specialized internal reward models tailored to specific enterprise needs, please contact the Snorkel AI team. |
Llama2 |
osunlp |
An expert used to QA tabular data |
The TableInstruct model is a transformer-based language model that can generate natural language instructions from structured data in tables. It is trained on the TableInstruct dataset, which contains over 100,000 examples of natural language instructions paired with their corresponding tables. The model can be used to generate instructions for a variety of tasks, such as data extraction, data summarization, and data analysis. It is licensed under the Creative Commons Attribution 4.0 International (CC BY 4.0) license. |
|
tulu-2-13b |
Llama2 |
Allen AI |
A helpful English based assistant with a balance of speed/performance and accuracy |
Tulu 2 13B is a fine-tuned version of Llama 2, trained on a mix of publicly available, synthetic, and human-created datasets. It is designed to act as a helpful assistant, primarily in English. The model is licensed under the AI2 ImpACT Low-risk license and is part of the Tulu V2 collection on Hugging Face. For more information, refer to the paper "Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2". |
tulu-2-70b |
Llama2 |
Allen AI |
A helpful English based assistant optimized for accuracy |
Tulu V2 70B is a fine-tuned version of Llama 2, trained on a mix of publicly available, synthetic, and human-created datasets. It is designed to act as a helpful assistant, primarily in English. The model is licensed under the AI2 ImpACT Low-risk license and is part of the Tulu V2 collection on Hugging Face. For more information, refer to the paper "Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2". |
tulu-2-7b |
Llama2 |
Allen AI |
A helpful assistant that can generate text, answer questions, and perform other language-related tasks |
Tulu 2 7B is a large language model fine-tuned from Llama 2 7B. It is trained on a mix of publicly available, synthetic, and human-created datasets. Tulu 2 7B is designed to act as a helpful assistant and can generate text, answer questions, and perform other language-related tasks. The model is licensed under the AI2 ImpACT Low-risk license and is available on Hugging Face. |
tulu-2-dpo-13b |
Llama2 |
Allen AI |
A helpful English based assistant with balanced speed/performance and accuracy |
Tulu V2 DPO 13B is a fine-tuned version of Llama 2 13B, trained on a mix of publicly available, synthetic, and human-created datasets using Direct Preference Optimization (DPO). It is a strong alternative to Llama 2 13B Chat and is primarily designed for English language processing. The model is licensed under the AI2 ImpACT Low-risk license and can be found on GitHub. The DPO recipe is from the Zephyr Beta model, and the model belongs to the Tulu V2 collection. |
tulu-2-dpo-70b |
Llama2 |
Allen AI |
A helpful assistant optimized for accuracy and tuned to human preferences |
Tulu V2 DPO 70B is a fine-tuned version of Llama 2 70B, trained on a mix of publicly available, synthetic, and human-created datasets using Direct Preference Optimization (DPO). It is primarily an English language model and is licensed under the AI2 ImpACT Low-risk license. The model is part of the Tulu V2 collection and can be found on Hugging Face. |
tulu-2-dpo-7b |
Llama2 |
Allen AI |
A fast/performant chat assistant tuned to human preferences |
Tulu V2 DPO 7B is a fine-tuned version of Llama 2 7B, trained on a mix of publicly available, synthetic, and human-created datasets using Direct Preference Optimization (DPO). It is a strong alternative to Llama 2 7B Chat and is primarily designed for English language processing. The model is licensed under the AI2 ImpACT Low-risk license and can be found on GitHub. The DPO recipe is from the Zephyr Beta model, and the model belongs to the Tulu V2 collection. |
Llama2 |
Universal-NER |
An instruction following model used for named entity recognition tasks (NER) |
It is a transformer-based neural network architecture that has been trained on a massive dataset of text and code. The model can generate human-like text, translate languages, write different types of creative content, and even write and debug code. It is a powerful tool that can be used for a variety of natural language processing tasks. |
|
v1olet_merged_dpo_7B |
Mistral |
v1olet |
A multilingual model |
DPO is a large language model that ranked 6th on the overall leaderboard and 1st in the 7B leaderboard. It is a multilingual model that can generate text in English. The model was developed by Trong-Hieu Nguyen-Mau and is licensed under the Apache 2.0 license. |
Llama2 |
Xwin-LM |
A mathematics expert with a balance of speed/performance and accuracy |
Xwin-Math is a series of powerful SFT LLMs for math problem based on LLaMA-2. It achieves state-of-the-art performance on math benchmarks such as MATH and GSM8K, outperforming previous open-source models. The largest model, Xwin-Math-70B-V1.0, achieves 31.8% on MATH and 87.0% on GSM8K, surpassing the previous best open-source models by 5.3 and 3.1 points, respectively. Xwin-Math also demonstrates strong mathematical synthesis capabilities on other benchmarks, approaching or even surpassing the performance of GPT-3.5-Turbo in some cases. |
|
Llama2 |
Xwin-LM |
A mathematics expert optimized for accuracy relative to its variants |
Xwin-Math is a series of powerful SFT LLMs for math problem based on LLaMA-2. It achieves state-of-the-art performance on math benchmarks such as MATH and GSM8K, outperforming previous open-source models. The largest model, Xwin-Math-70B-V1.0, achieves 31.8% on MATH and 87.0% on GSM8K, surpassing the previous best open-source models by 5.3 and 3.1 points, respectively. Xwin-Math also demonstrates strong mathematical synthesis capabilities on other benchmarks, approaching or even surpassing the performance of GPT-3.5-Turbo in some cases. |
|
Llama2 |
Xwin-LM |
A mathematics expert optimized for speed/performance relative to its variants |
Xwin-Math is a series of powerful SFT LLMs for math problems based on LLaMA-2. It achieves state-of-the-art performance on various math benchmarks, surpassing previous open-source models. The largest model, Xwin-Math-70B-V1.0, achieves 31.8% on MATH and 87.0% on GSM8K, outperforming the previous best open-source models by a significant margin. Xwin-Math also demonstrates strong mathematical reasoning capabilities on other benchmarks, approaching or even surpassing the performance of GPT-3.5-Turbo in some cases. |
|
zephyr-7b-beta |
Mistral |
HuggingFaceH4 |
A capable and helpful chat assistant. This model is particularly great at scenario building and roleplaying. |
Zephyr-7B-β is a 7B parameter language model fine-tuned on a mix of publicly available, synthetic datasets using Direct Preference Optimization (DPO). It is a more helpful version of mistralai/Mistral-7B-v0.1 and is currently the highest ranked 7B chat model on the MT-Bench and AlpacaEval benchmarks. |
e5-mistral-7b-instruct |
Mistral |
intfloat |
An embedding model that utilizes the Mistral framework. |
E5 Mistral 7B Instruct is an embedding model that utilizes the Mistral framework. While E5 Mistral 7B Instruct has multilingual capabilities, it is recommended for English use, as it does not perform comparatively well in multilingual benchmarks. Some prompting is necssary for queries, but documents can be used without modification. |
KNN-Classifier-Samba-1-Chat-Router |
Mistral |
SambaNova Systems |
A router comprised of two components that is best suited for chat related queries. |
A router comprised of two components. The first component is the e5-mistral-7b-instruct embedding model, which is used to embed the users' query into a vector space. The second component is a KNN classifier. It chooses the best expert to be used for the user’s query. This router is best suited for chat related queries. |
KNN-Classifier-Samba-1-Instruct-Router |
Mistral |
SambaNova Systems |
A router comprised of two components that is best suited for chat related queries. |
A router comprised of two components. The first component is the e5-mistral-7b-instruct embedding model, which is used to embed the users' query into a vector space. The second component is a KNN classifier. It chooses the best expert to be used for the user’s query. This router is best suited for chat related queries. |
Swallow-7b-instruct-v0.1 |
Llama 2 |
Tokyotech |
A deep-learning model designed for Japanese and English languages. |
Swallow 7B Instruct V0.1 is part of the Swallow model family, developed by TokyoTech-LLM, which is a series of deep-learning models designed for Japanese and English languages. Pre-trained using data from the Llama 2 family, the model incorporates Japanese language information and employs supervised fine-tuning (SFT) for improved performance. Available in various sizes, including 7 billion, 13 billion, and 70 billion parameters. It is important to note that these models are in the early stages of development and have not been optimized for human intent and safety. |
Swallow-13b-instruct-v0.1 |
Llama 2 |
Tokyotech |
A deep-learning model designed for Japanese and English languages. |
Swallow 13B Instruct V0.1 is part of the Swallow model family, developed by TokyoTech-LLM, which is a series of deep-learning models designed for Japanese and English languages. Pre-trained using data from the Llama 2 family, the model incorporates Japanese language information and employs supervised fine-tuning (SFT) for improved performance. Available in various sizes, including 7 billion, 13 billion, and 70 billion parameters. It is important to note that these models are in the early stages of development and have not been optimized for human intent and safety. |
Swallow-70b-instruct-v0.1 |
Llama 2 |
Tokyotech |
A deep-learning model designed for Japanese and English languages. |
Swallow 70B Instruct V0.1 is part of the Swallow model family, developed by TokyoTech-LLM, which is a series of deep-learning models designed for Japanese and English languages. Pre-trained using data from the Llama 2 family, the model incorporates Japanese language information and employs supervised fine-tuning (SFT) for improved performance. Available in various sizes, including 7 billion, 13 billion, and 70 billion parameters. It is important to note that these models are in the early stages of development and have not been optimized for human intent and safety. |
Llama 2 |
Tokyotech |
The 7B NVE instruct does not contain vocabulary expansion. The model’s capabilities span multiple natural language processing tasks, such as question answering, machine reading comprehension, and automatic summarization. |
The Swallow model, pre-trained with Japanese language data from the Llama 2 family, offers various versions tailored for different use cases. These versions include Swallow-hf, Swallow-instruct-hf, and others with sizes ranging from 7B to 70B parameters. This 7B NVE Instruct version does not contain vocabulary expansion. The model’s capabilities span multiple natural language processing tasks, such as question answering, machine reading comprehension, and automatic summarization. The Swallow model outperforms Llama 2 in most tasks, especially Japanese related tasks, with larger models demonstrating better performance. The deep-learning models are in the early stages of development and have limitations in terms of human intent and safety. The Swallow model’s pre-training on diverse datasets and instruction tuning enhances its understanding and performance in generating high-quality Japanese text. |
|
Llama 2 |
Tokyotech |
The 70B NVE Instruct version does not contain vocabulary expansion. The model’s capabilities span multiple natural language processing tasks, such as question answering, machine reading comprehension, and automatic summarization. |
The Swallow model, pre-trained with Japanese language data from the Llama 2 family, offers various versions tailored for different use cases. These versions include Swallow-hf, Swallow-instruct-hf, and others with sizes ranging from 7B to 70B parameters. This 70B NVE Instruct version does not contain vocabulary expansion. The model’s capabilities span multiple natural language processing tasks, such as question answering, machine reading comprehension, and automatic summarization. The Swallow model outperforms Llama 2 in most tasks, especially Japanese related tasks, with larger models demonstrating better performance. The deep-learning models are in the early stages of development and have limitations in terms of human intent and safety. The Swallow model’s pre-training on diverse datasets and instruction tuning enhances its understanding and performance in generating high-quality Japanese text. |
|
ELYZA-japanese-llama-2-7b |
Llama 2 |
Elyza |
This model is intended for natural language processing and machine learning tasks. The model’s capabilities make it suitable for various use cases, such as text generation, translation, and sentiment analysis. |
The ELYZA-japanese-Llama-2-7b deep-learning model, designed specifically for the Japanese language, is based on Llama2 and boasts a 32,000 word vocabulary size and 6.27 billion parameters. This model, along with its instruct variant, is intended for natural language processing and machine learning tasks. The model’s capabilities make it suitable for various use cases, such as text generation, translation, and sentiment analysis. Note that limitations of this model may include biases in the training data, potential misinterpretations, and the need for careful fine-tuning to achieve optimal results. |
Llama 2 |
NousResearch |
The Nous-Hermes-Llama2-7b model is a Hermes based language model fine-tuned on more than 300,000 instructions. |
The Nous-Hermes-Llama2-7b model is a Hermes based language model fine-tuned on more than 300,000 instructions. This model delivers standout performance with longer responses and reduced hallucination rate. Trained on synthetic outputs from diverse sources, the model is versatile for a wide range of language tasks. |
|
Llama 2 |
NousResearch |
The Nous-Hermes-Llama2-13b model is a Hermes based language model fine-tuned on more than 300,000 instructions. |
The Nous-Hermes-Llama2-13b model is a Hermes based language model fine-tuned on more than 300,000 instructions. This model delivers standout performance with longer responses and reduced hallucination rate. Trained on synthetic outputs from diverse sources, the model is versatile for a wide range of language tasks. |
|
CodeLlama-70b-Python-hf |
Llama 2 |
Meta |
Code Llama is designed for general code synthesis and understanding. The 70B Python specialist version is available in three variations: base, Python, and Instruct. Key features include code completion and Python expertise. |
Code Llama, which is designed for general code synthesis and understanding, is a series of pretrained and fine-tuned generative text models varying in size from 7 to 34 billion parameters. The 70B Python specialist version is available in three variations: base, Python, and Instruct. Key features include code completion and Python expertise. Using an optimized transformer architecture, the model was trained between January 2023 and July 2023 for commercial and research applications in English and relevant programming languages. Limitations include unpredictable outputs, requiring safety testing and tuning before deployment. Code Llama’s usage is intended for English only and should comply with all applicable laws. For more information, consult the research paper or the responsible use guide. |
CodeLlama-70b-Instruct-hf |
Llama 2 |
Meta |
Code Llama is designed for general code synthesis and understanding. The 70B Instruct specialist version is available in three variations: base, Python, and Instruct. Key features include code completion, infilling, and following instructions. |
Code Llama, which is designed for general code synthesis and understanding, is a series of pretrained and fine-tuned generative text models varying in size from 7 to 34 billion parameters. The 70B Instruct specialist version is available in three variations: base, Python, and Instruct. Key features include code completion, infilling, and following instructions. Using an optimized transformer architecture, the model was trained between January 2023 and July 2023 for commercial and research applications in English and relevant programming languages. Limitations include unpredictable outputs, requiring safety testing and tuning before deployment. Code Llama’s usage is intended for English only and should comply with all applicable laws. For more information, consult the research paper or the responsible use guide. |
SambaLingo-70b-Hungarian-Chat |
Llama2 |
SambaNova Systems |
SambaLingo-Hungarian is an English-Hungarian bilingual model. SambaLingo is a collection of language expert models trained on llama-2-70b by SambaNova. |
SambaLingo-Hungarian is an English-Hungarian bilingual model. SambaLingo is a collection of language expert models trained on llama-2-70b by SambaNova. SambaLingo achieves state-of-the-art performance on various multilingual benchmarks. The chat versions of the models are human-aligned with DPO. Notably, eval consistency is favored in SambaLingo over other top-tier open source instruction-tuned multilingual models. |
SambaLingo-70b-Arabic-Chat |
Llama2 |
SambaNova Systems |
SambaLingo-Hungarian is an English-Arabic bilingual model. SambaLingo is a collection of language expert models trained on llama-2-70b by SambaNova. |
SambaLingo-Hungarian is an English-Arabic bilingual model. SambaLingo is a collection of language expert models trained on llama-2-70b by SambaNova. SambaLingo achieves state-of-the-art performance on various multilingual benchmarks. The chat versions of the models are human-aligned with DPO. Notably, eval consistency is favored in SambaLingo over other top-tier open source instruction-tuned multilingual models. |
SambaLingo-70b-Thai-Chat |
Llama2 |
SambaNova Systems |
SambaLingo-Hungarian is an English-Thai bilingual model. SambaLingo is a collection of language expert models trained on llama-2-70b by SambaNova. |
SambaLingo-Hungarian is an English-Thai bilingual model. SambaLingo is a collection of language expert models trained on llama-2-70b by SambaNova. SambaLingo achieves state-of-the-art performance on various multilingual benchmarks. The chat versions of the models are human-aligned with DPO. Notably, eval consistency is favored in SambaLingo over other top-tier open source instruction-tuned multilingual models. |
Magicoder-S-DS-6.7B |
Llama 2 |
Kukedlc |
The Magicoder deep-learning model family utilizes OSS-Instruct, a method that incorporates open-source code snippets to create high-quality instruction data for coding tasks. |
The Magicoder deep-learning model family utilizes OSS-Instruct, a method that incorporates open-source code snippets to create high-quality instruction data for coding tasks. Fine-tuned from the deepseek-coder-6.7b-base model, Magicoder models are trained with Magicoder-OSS-Instruct-75K and Magicoder-Evol-Instruct-110K datasets. Designed specifically for coding applications, it may not excel in non-coding tasks and can occasionally produce errors or misleading content. Users should be aware of the model’s limitations and biases when using it. |
Magicoder-S-DS-6.7B-16k |
Llama 2 |
Kukedlc |
The Magicoder deep-learning model family utilizes OSS-Instruct, a method that incorporates open-source code snippets to create high-quality instruction data for coding tasks. |
The Magicoder deep-learning model family utilizes OSS-Instruct, a method that incorporates open-source code snippets to create high-quality instruction data for coding tasks. Fine-tuned from the deepseek-coder-6.7b-base model, Magicoder models are trained with Magicoder-OSS-Instruct-75K and Magicoder-Evol-Instruct-110K datasets. Designed specifically for coding applications, it may not excel in non-coding tasks and can occasionally produce errors or misleading content. Users should be aware of the model’s limitations and biases when using it. This specific model supports up to 16K sequence length size. |
BioMistral-7B |
Mistral |
BioMistral |
BioMistral is an open-source LLM specifically designed for the biomedical domain. It is built upon the Mistral foundation model and further pretrained on PubMed Central. |
BioMistral is an open-source LLM specifically designed for the biomedical domain. It is built upon the Mistral foundation model and further pretrained on PubMed Central. It demonstrates superior performance compared to existing open-source medical models and competes with proprietary counterparts. The model suite includes BioMistral-7B, BioMistral-7B-DARE, BioMistral-7B-TIES, and BioMistral-7B-SLERP. Each of these are optimized for various medical domain-related tasks. BioMistral performs the best on Clinical KG. The models can be used for text classification, information retrieval, and question-answering. However, it is important to note that BioMistral is intended for research purposes only and should not be used in professional health or medical contexts until it undergoes further testing and alignment with specific use cases. |
BioMistral-7B-DARE |
Mistral |
BioMistral |
BioMistral-7B-DARE is merged using DARE method with BioMistral-7B as the base. BioMistral-7B is an open-source LLM specifically designed for the biomedical domain. |
BioMistral-7B-DARE is merged using DARE method with BioMistral-7B as the base. BioMistral-7B is an open-source LLM specifically designed for the biomedical domain. It is built upon the Mistral foundation model and further pretrained on PubMed Central. It demonstrates superior performance compared to existing open-source medical models and competes with proprietary counterparts. The model suite includes BioMistral-7B, BioMistral-7B-DARE, BioMistral-7B-TIES, and BioMistral-7B-SLERP. Each of these are optimized for various medical domain-related tasks. BioMistral-7B-DARE performs the best on medical genetics, college biology/medicine, and MedQA. The models can be used for text classification, information retrieval, and question-answering. However, it is important to note that BioMistral is intended for research purposes only and should not be used in professional health or medical contexts until it undergoes further testing and alignment with specific use cases. |
BioMistral-7B-TIES |
Mistral |
BioMistral |
BioMistral-7B-TIES is merged using TIES method with BioMistral-7B as the base. BioMistral-7B is an open-source LLM specifically designed for the biomedical domain. |
BioMistral-7B-TIES is merged using TIES method with BioMistral-7B as the base. BioMistral-7B is an open-source LLM specifically designed for the biomedical domain. It is built upon the Mistral foundation model and further pretrained on PubMed Central. It demonstrates superior performance compared to existing open-source medical models and competes with proprietary counterparts. The model suite includes BioMistral-7B, BioMistral-7B-DARE, BioMistral-7B-TIES, and BioMistral-7B-SLERP. Each of these are optimized for various medical domain-related tasks. BioMistral-7B-TIES peforms the best on anatomy. The models can be used for text classification, information retrieval, and question-answering. However, it is important to note that BioMistral is intended for research purposes only and should not be used in professional health or medical contexts until it undergoes further testing and alignment with specific use cases. |
BioMistral-7B-SLERP |
Mistral |
BioMistral |
BioMistral-7B-SLERP is merged using SLERP method with BioMistral-7B and Mistral-7B-Instruct-v0.1. BioMistral-7B is an open-source LLM specifically designed for the biomedical domain. |
BioMistral-7B-SLERP is merged using SLERP method with BioMistral-7B and Mistral-7B-Instruct-v0.1. BioMistral-7B is an open-source LLM specifically designed for the biomedical domain. It is built upon the Mistral foundation model and further pretrained on PubMed Central. It demonstrates superior performance compared to existing open-source medical models and competes with proprietary counterparts. The model suite includes BioMistral-7B, BioMistral-7B-DARE, BioMistral-7B-TIES, and BioMistral-7B-SLERP. Each of these are optimized for various medical domain-related tasks. BioMistral-7B-SLERP performs the best on PubMedQA. The models can be used for text classification, information retrieval, and question-answering. However, it is important to note that BioMistral is intended for research purposes only and should not be used in professional health or medical contexts until it undergoes further testing and alignment with specific use cases. |
Saul-Instruct-v1 |
Mistral |
Equall |
Saul-Instruct-v1 model is a large, legal domain-specific language model designed for generating legal text. |
Saul-Instruct-v1 model is a large, legal domain-specific language model designed for generating legal text. Based on the Mistral-7B model, it utilizes a transformers Model Type 7B for English Natural Language Processing tasks. This model is optimized for generation tasks and intended exclusively for legal use cases. However, it may occasionally produce inaccurate or nonsensical results due to its LLM technology and less robust performance compared to larger models like the 70B variant. |
WestLake-7B-v2-laser-truthy-dpo |
Mistral |
marcadeliccc |
The WestLake-7B-v2-laser-truthy-dpo deep-learning model is designed for natural language processing, specifically targeting multi-turn conversations. |
The WestLake-7B-v2-laser-truthy-dpo deep-learning model is designed for natural language processing, specifically targeting multi-turn conversations. This model is trained on the jondurbin/truthy-dpo-v0.1 dataset. It is capable of understanding and adjusting to diverse inputs while maintaining a consistent flow of information exchange, promoting socially unbiased and positive interactions. The model’s performance is demonstrated through various metrics, including an average score of 75.37, 73.89 on the AI2 Reasoning Challenge (25-shot), 88.85 on HellaSwag (10-shot), 64.84 on MMLU (5-shot), 69.81 on TruthfulQA (0-shot), 86.66 on Winogrande (5-shot), and 68.16 on GSM8k (5-shot). |
EmertonMonarch-7B |
Mistral |
yleo |
EmertonMonarch-7B is a Mistral fine-tuned, deep-learning model derived from mlabonne/Monarch-7B. |
EmertonMonarch-7B is a Mistral fine-tuned, deep-learning model derived from mlabonne/Monarch-7B. It is specifically designed for enhanced performance using the DPO technique and the Emerton preference dataset. |
typhoon-7b |
Mistral |
scb10x |
Typhoon-7B is a 7 billion parameter pretrained Thai large language model. |
Typhoon-7B is a 7 billion parameter pretrained Thai large language model. Based on Mistral-7B, it excels in Thai examination benchmarks and rivals the performance of other popular models while offering better efficiency in tokenizing Thai text. This model supports both Thai and English languages. Typhoon-7B is designed for various use cases, such as text generation, translation, and summarization. However, it may not follow human instructions without one/few-shot learning or instruction fine-tuning. |
Mistral |
NousResearch |
Genstruct 7B is a powerful deep-learning model designed to generate valid instructions from a raw text corpus. |
Genstruct 7B is a powerful deep-learning model designed to generate valid instructions from a raw text corpus. Inspired by Ada-Instruct, it utilizes user-provided context passages to ground the generated instructions, enabling the creation of complex scenarios requiring detailed reasoning. This versatile model is capable of generating grounded generations, complex questions, and complex responses. Genstruct 7B is intended for use in various applications where generating valid instructions from contextual information is essential. However, it is important to note that this model may have limitations in terms of understanding the nuances of human language and context, which could lead to inaccuracies or misunderstandings in the generated instructions. |
|
Mistral-7B-OpenOrca |
Mistral |
Open-Orca |
The deep-learning model "MistralOrca" has been created by fine-tuning the OpenOrca dataset on top of Mistral 7B. |
The deep-learning model "MistralOrca" has been created by fine-tuning the OpenOrca dataset on top of Mistral 7B. It outperforms all other 7B and 13B models in its class according to HF Leaderboard evals. |
OpenHermes-2p5-Mistral-7B |
Mistral |
teknium |
OpenHermes 2.5 Mistral 7B is an advanced deep-learning model that demonstrates improved performance in various non-code benchmarks, including TruthfulQA, AGIEval, and the GPT4All suite. |
OpenHermes 2.5 Mistral 7B is an advanced deep-learning model that demonstrates improved performance in various non-code benchmarks, including TruthfulQA, AGIEval, and the GPT4All suite. With a significant increase in its humaneval score from 43% to 50.7%, this model has been trained on 1 million high-quality data entries from various open datasets. OpenHermes 2.5 can be used for various natural language processing tasks, such as text generation, translation, and summarization. |
Nous-Hermes-2-Mistral-7B-DPO |
Mistral |
NousResearch |
Nous Hermes 2 on Mistral 7B DPO is a cutting-edge, deep-learning model. Compared to its predecessor, OpenHermes 2.5, it delivers superior performance on various benchmarks, such as AGIEval, BigBench, GPT4All, and TruthfulQA. |
Nous Hermes 2 on Mistral 7B DPO is a cutting-edge, deep-learning model. Compared to its predecessor, OpenHermes 2.5, it delivers superior performance on various benchmarks, such as AGIEval, BigBench, GPT4All, and TruthfulQA. With significant improvement across all tested benchmarks and an average improvement of 73.72 in GPT4All, this model offers impressive capabilities. The AGIEval benchmarks achieved an average score of 43.63, while the BigBench benchmarks achieved an average score of 41.94. The TruthfulQA benchmarks delivered a score of 0.5642 for the mc2 metric. |
Mistral |
NexusFlow |
Starling-LM-7B-beta is a large language model trained through Reinforcement Learning from AI Feedback (RLAIF). |
Starling-LM-7B-beta is a large language model trained through Reinforcement Learning from AI Feedback (RLAIF). It is designed for use as a chatbot in various applications, such as customer support, information provision, and entertainment. Developed by the Nexusflow Team, it is fine-tuned from Openchat-3.5-0106 and based on Mistral-7B-v0.1, utilizing the upgraded reward model Starling-RM-34B and a new reward training and policy tuning pipeline. |
|
codegemma-7b |
Gemma |
CodeGemma is a series of deep-learning models developed by Google for text-to-text and text-to-code tasks, such as code completion and generation from natural language. |
CodeGemma is a series of deep-learning models developed by Google for text-to-text and text-to-code tasks, such as code completion and generation from natural language. It comes in three variants with 7 billion and 2 billion parameters, optimized for code completion, generation, and instruction following. CodeGemma-7b is specifically good at code completion and generation from natural language. It is trained on an additional 500 billion tokens of English language data from public code repositories, open-source math datasets, and synthetically generated code. Ethical concerns guide the development of these models, and guidelines are followed to ensure responsible AI development. CodeGemma offers high-performance, open-source implementations and demonstrates superior performance in coding benchmark evaluations compared to similar-sized models. |
|
codegemma-7b-it |
Gemma |
CodeGemma is a series of deep-learning models developed by Google for text-to-text and text-to-code tasks, such as code completion and generation from natural language. |
CodeGemma is a series of deep-learning models developed by Google for text-to-text and text-to-code tasks, such as code completion and generation from natural language. It comes in three variants with 7 billion and 2 billion parameters, optimized for code completion, generation, and instruction following. CodeGemma-7b-it is specifically good at generation from natural language, chatting, and instruction following. It is trained on an additional 500 billion tokens of English language data from public code repositories, open-source math datasets, and synthetically generated code. Ethical concerns guide the development of these models, and guidelines are followed to ensure responsible AI development. CodeGemma offers high-performance, open-source implementations and demonstrates superior performance in coding benchmark evaluations compared to similar-sized models. |
|
Meta-Llama-3-8B |
Llama3 |
Meta |
Meta’s Llama 3 family introduces large language models with 8B and 70B parameter versions. The Meta-Llama-3-8B model is optimized for a variety of natural language generation tasks. |
Meta’s Llama 3 family introduces large language models with 8B and 70B parameter versions. The Meta-Llama-3-8B model is optimized for a variety of natural language generation tasks. This model was pretrained on over 15 trillion tokens of data from publicly available sources. The models are auto-regressive, using an optimized transformer architecture, and trained on publicly available online data. The models are designed for English language use in commercial and research settings, suitable for natural language generation tasks. However, they are not intended for use in violation of any laws or regulations or in languages other than English unless developers comply with specific licensing and policy requirements. |
Meta-Llama-3-8B-Instruct |
Llama3 |
Meta |
Meta’s Llama 3 family introduces large language models with 8B and 70B parameter versions. The Meta-Llama-3-8B-Instruct model is optimized for dialogue use cases and prioritizing helpfulness and safety. |
Meta’s Llama 3 family introduces large language models with 8B and 70B parameter versions. The Meta-Llama-3-8B-Instruct model is optimized for dialogue use cases and prioritizing helpfulness and safety. These models outperform many open-source chat models on industry benchmarks and employ supervised fine-tuning and reinforcement learning with human feedback. The models are auto-regressive, using an optimized transformer architecture, and trained on publicly available online data. The models are designed for English language use in commercial and research settings, suitable for chat assistant applications, and natural language generation tasks. However, they are not intended for use in violation of any laws or regulations or in languages other than English unless developers comply with specific licensing and policy requirements. |
Llama3 |
Meta |
Llama Guard 2 is an 8 billion parameter deep-learning model designed to safeguard human-AI conversations by classifying content in both prompts and responses as safe or unsafe. |
Llama Guard 2 is an 8 billion parameter deep-learning model designed to safeguard human-AI conversations by classifying content in both prompts and responses as safe or unsafe. Based on Llama 3, it predicts safety labels for 11 categories using the MLCommons taxonomy of hazards. The model is fine-tuned for causal language modeling and outperforms other content moderation APIs in internal testing. However, it has limitations, such as not addressing Election and Defamation categories, and may require additional solutions for specific use cases. |
|
Meta-Llama-3-70B |
Llama3 |
Meta |
Meta’s Llama 3 family introduces large language models with 8B and 70B parameter versions. The Meta-Llama-3-70B model is optimized for a variety of natural language generation tasks. |
Meta’s Llama 3 family introduces large language models with 8B and 70B parameter versions. The Meta-Llama-3-70B model is optimized for a variety of natural language generation tasks. This model was pretrained on over 15 trillion tokens of data from publicly available sources. The models are auto-regressive, using an optimized transformer architecture, and trained on publicly available online data. The models are designed for English language use in commercial and research settings, suitable for natural language generation tasks. However, they are not intended for use in violation of any laws or regulations or in languages other than English unless developers comply with specific licensing and policy requirements. |
Meta-Llama-3-70B-Instruct |
Llama3 |
Meta |
Meta’s Llama 3 family introduces large language models with 8B and 70B parameter versions. The Meta-Llama-3-70B-Instruct model is optimized for dialogue use cases and prioritizing helpfulness and safety. |
Meta’s Llama 3 family introduces large language models with 8B and 70B parameter versions. The Meta-Llama-3-70B-Instruct model is optimized for dialogue use cases and prioritizing helpfulness and safety. These models outperform many open-source chat models on industry benchmarks and employ supervised fine-tuning and reinforcement learning with human feedback. The models are auto-regressive, using an optimized transformer architecture, and trained on publicly available online data. The models are designed for English language use in commercial and research settings, suitable for chat assistant applications, and natural language generation tasks. However, they are not intended for use in violation of any laws or regulations or in languages other than English unless developers comply with specific licensing and policy requirements. |
Llama2 |
defog |
sqlcoder-7b-2 is a large language model designed for natural language to SQL generation. |
sqlcoder-7b-2 is a large language model designed for natural language to SQL generation. Finetuned from the CodeLlama-7B model, SQLCoder can convert text input into SQL queries, making it a valuable tool for natural language processing and database management tasks. This model serves as an analytics tool for non-technical users to explore data in their SQL databases. |
Deploy a Samba-1 endpoint
With the SambaStudio platform, you can generate predictions by deploying Samba-1 to an endpoint. Follow the steps described in Create a CoE endpoint using the GUI to deploy a Samba-1 endpoint.
Usage
Once your Samba-1 endpoint has been deployed, you can interact with it as demonstrated in the example curl request below.
curl -X POST \
-H 'Content-Type: application/json' \
-H 'key: <your-endpoint-key>' \
--data '{"inputs":["{\"conversation_id\":\"conversation-id\",\"messages\":[{\"message_id\":0,\"role\":\"user\",\"content\":\"\"}]}"],"params":{"do_sample":{"type":"bool","value":"true"},"max_tokens_to_generate":{"type":"int","value":"1024"},"process_prompt":{"type":"bool","value":"true"},"repetition_penalty":{"type":"float","value":"1"},"select_expert":{"type":"str","value":"llama-2-7b-chat-hf"},"stop_sequences":{"type":"str","value":""},"temperature":{"type":"float","value":"0.7"},"top_k":{"type":"int","value":"50"},"top_p":{"type":"float","value":"0.95"}}}' '<your-sambastudio-domain>/api/predict/nlp/<project-key>/<endpoint>'The example above makes a call to the llama-2-7b-chat-hf expert via the property "select_expert":{"type":"str","value":"llama-2-7b-chat-hf"}.
Samba-1 in the Playground
The Playground provides an in-platform experience for generating predictions using a deployed Samba-1 endpoint.
|
When selecting an endpoint deployed from Samba-1.1, please ensure that Process prompt is turned On in the Tuning Parameters. 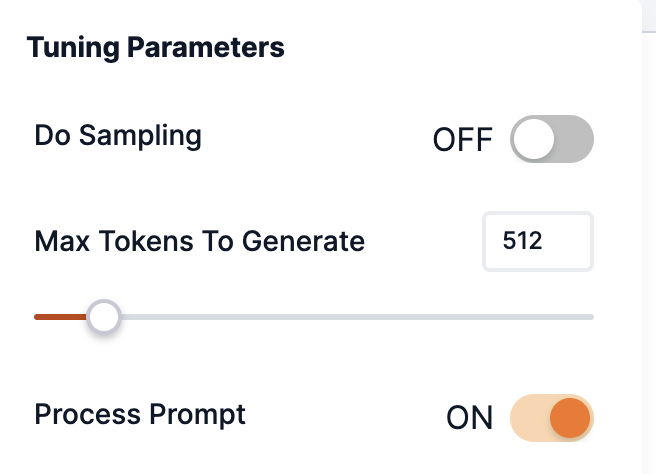
|
-
Select a CoE expert or router describes how to choose a Samba-1 expert to use with your prompt in the Playground.
-
To get optimal responses from a task-specific Samba-1 expert in the Playground, use the corresponding template to format your inputs.