How to use tensor parallel mode (Beta)
Internally, SambaFlow supports several types of model parallelization. Model parallelization makes running the model (training, fine-tuning, etc) more efficient. You have control over parallelization in these ways:
-
Data parallel mode: You can compile and run the model in data parallel mode, discussed here. Some applications run much faster in data parallel mode. See How to use data parallel mode.
-
Tensor parallel mode: You can instruct the compiler to perform tensor parallel optimization, which also improves efficiency when you run the model. Enhancements to tensor parallel compilation in release 1.18 automate and simplify compiling a model to run on multiple RDUs. Using tensor parallel during compilation:
-
Improves performance during training, fine tuning, and inference.
-
Helps in situations where large models exceed the memory limit of a single RDU.
-
What is tensor parallel compilation?
With tensor parallel compilation, some dimensions of tensors are split across RDUs. Users can control how many RDUs to use, and whether to use batch mode or weight mode.
Consider the following example, which starts with this graph:
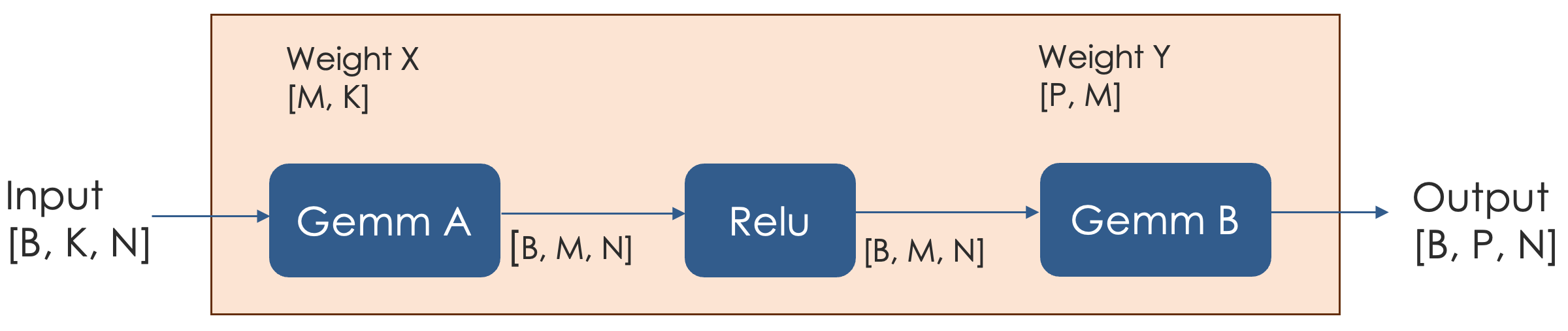
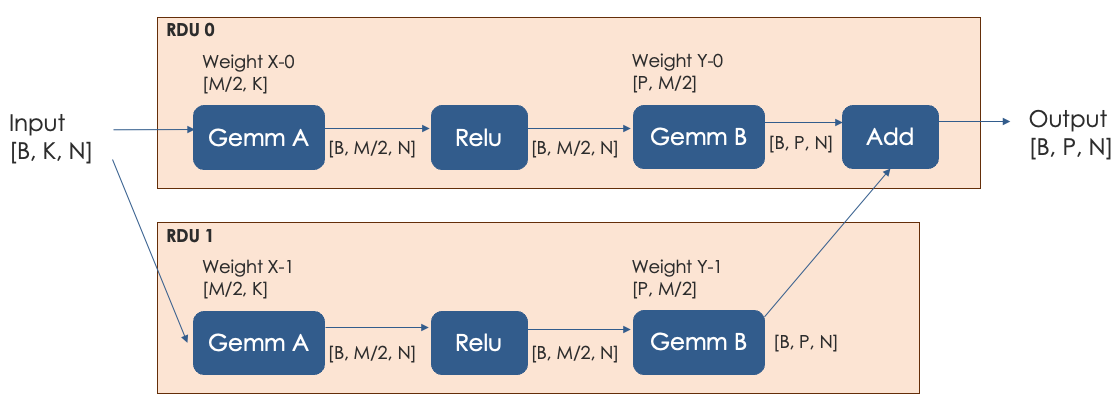
When the compiler performs a split on dimension M:
-
RDU 0 and RDU 1 both have half of the computation workload.
-
The X-0/Y-0 and X-1/Y-1 weights are each half of the original weight and weight tensors.
-
At the end of compilation, we perform an additional
Addoperation to accumulate the results from both RDUs to get the final output. -
There might be p2p communication between the two RDUs
-
At the beginning (for the input)
-
Right before the
Addoperation where RDU 1 might need to send its result to RDU 0.
-
How to use tensor parallel compilation
When you compile your model, you can use command-line arguments to specify and customize tensor parallel mode.
Turn on tensor parallel mode
To compile using tensor parallel mode, you specify --tensor-parallel on the command line. You must specify batch or weight.
If you’re not running in tensor parallel mode and you specify the number of chips with --n-chips, the default is batch. With tensor parallel mode, specifying batch or weight is required.
|
$ python <model.py> compile --pef-name <pef_name> --tensor-parallel [batch|weight]-
Batch mode splits on the batch dimension.
-
Weight mode splits on the weight dimension.
Which mode to choose depends on the relative size of the data tensors and the weight tensors.
-
If the data tensors are larger than the weight tensors, then batch mode results in better performance.
-
If the weight tensors are larger than data tensors, then weight mode results in better performance.
| Specifying tensor parallel mode only makes sense for compilation. The generated PEF file encapsulates the properties that are specified by the arguments. During training and inference, the information that’s encapsulated in the PEF is then used to run the model. |
Specify the number of RDUs (chips)
By default, tensor parallel compilation uses one RDU. You can use --n-chips to change the number of RDUs.
$ python <model.py> compile --pef-name <pef_name> --tensor-parallel [batch|weight] --n-chips [1|2|8]| Tensor parallel mode works only within one node. On currently shipping hardware, the maximum number of RDUs is 8 per node. |
How to use tensor parallel mode with an operator fusion rule
If you are compiling with o1, you can customize the compiler’s behavior with an operator fusion rule YAML file. In that YAML file, you can also customize the behavior of tensor parallel weight mode.
| Operator fusion rules work only with weight mode. Batch mode ignores any yaml file tensor parallel dimension settings. |
If you’re using Gemm heuristic, you can specify the dimension to be either M or K, as follows:
heuristic:
name: SAFE_GEMM
tensor parallel_dim: [M|K]The M and K dimension specify either split M or K dimension of the weight tensors of the gemm operation. You can change the tensor parallel dimension for better performance. For NLP models the following settings usually results in the best performance:
-
Tensor parallel dimension of QKV is M
-
Attention projection gemm is K
-
FFN0 is M
-
FFN1 is K
Here is an example for part of Llama fusion rule:
Operator fusion rule example
llama2_qkv:
priority: 4
heuristic:
name: SAFE_GEMM
tensor parallel_dim: [M|K]
pattern:
to_8:
op_type: to
child: ln_pow_9
required: false
ln_pow_9:
op_type: pow
child: ln_mean_10
ln_mean_10:
op_type: mean
child: ln_add_11
ln_add_11:
op_type: add
child: ln_rsqrt_12
ln_rsqrt_12:
op_type: rsqrt
child: ln_mul_13
ln_mul_13:
op_type: mul
child: ln_mul_15
ln_mul_15:
op_type: mul
children:
- q_cast
- k_cast
- v_cast
linear_q_16:
op_type: linear
linear_k_17:
op_type: linear
linear_v_18:
op_type: linear
q_cast:
op_type: type_
child: linear_q_16
required: false
k_cast:
op_type: type_
child: linear_k_17
required: false
v_cast:
op_type: type_
child: linear_v_18
required: false
llama2_self_attn_proj:
priority: 3
heuristic:
name: SAFE_GEMM
tensor parallel_dim: K
pattern:
attn_outensor parallelut_cast:
op_type: type_
required: false
child: linear_48
linear_48:
op_type: linear
child: post_linear_cast
post_linear_cast:
op_type: type_
required: false
child: add_49
add_49:
op_type: add
child: pre_rmsnorm_cast
pre_rmsnorm_cast:
op_type: to
required: false
children:
- ln_pow_50
- ln_mul_54
ln_pow_50:
op_type: pow
child: ln_mean_51
ln_mean_51:
op_type: mean
child: ln_add_52
ln_add_52:
op_type: add
child: ln_rsqrt_53
ln_rsqrt_53:
op_type: rsqrt
child: ln_mul_54
ln_mul_54:
op_type: mul
child: post_rmsnorm_cast
post_rmsnorm_cast:
op_type: to
required: false
child: ln_mul_56
ln_mul_56:
op_type: mulSizing guidelines
The shape of your model determines:
-
Whether it’s a good idea to compile your model with tensor parallel turned on.
-
Which mode (batch mode or weight mode) gives the best results.
Here are some general guidelines:
-
For large models, more RDUs ensure that the required memory does not exceed what is available. In addition, the compiler can derive a better solution for large models with the flexibility of more RDUs.
-
For small models, allocating more RDUs than required can result in low utilization with much of the RDU capacity being idle. In addition, RDU communication overhead can exceed the gains from the increased compute power of additional RDUs.
The following guidelines help you make the right decision.
| These guidelines are for SN-10 2PDU (aka SN20) and SN30 systems. We’ll add guidelines for SN40L at a later date. |
Model-specific size guidance
You must set the tensor parallel size for each model correctly. The following table shows suggested values:
| Model size | Number of RDUs, mode (SN20) | Number of RDUs, mode (SN30) |
|---|---|---|
< 20B |
1 |
1, batch mode |
20B - 40B |
2, weight mode |
1, weight mode |
40B - 80B |
4, weight mode |
2, weight mode |
80B - 176B |
8, weight mode |
4 or 8, weight mode |
Guidelines for other model parameters
Hidden dimension size
Model size is related to the size of the hidden dimension size and to the number of layers. In module tests where we only have the hidden dimension size, we suggest testing following tensor parallel size for different hidden dimsion sizes.
| Hidden dimension size | SN20 | SN30 |
|---|---|---|
<= 4096 |
1 or 2, weight mode |
1, batch mode or weight mode |
4096 - 8192 |
2 or 4, weight mode |
1 or 2, weight mode |
>= 8192 |
4 or 8, weight mode |
2 or 4, weight mode |
Number of attention heads
Number of attention heads does not affect tensor parallel size. However, ensure that the number of attention heads is divisible by the tensor parallel size.
Sequence Length
The suggestions in the tables above are based on regular sequence length not greater than 4K. If you hit the memory limit:
-
First reduce the batch size.
-
If compilation still hits the memory limit for batch size 1, increase the tensor parallel size.
| Use flash attention for >=8k sequence length. |
Precision
The suggestions above are based on BF16 precision. If you’re using FP32 or mixed precision and you hit the memory limit, increase the number of RDUs.
Cached Inference Multigraph
For cached inference, the utilization bottleneck is on weight loading rather than computation. SambaNova recommends using more RDUs for tensor parallel weight mode on cached inference multigraph. For example, for Llama 7B or 13B, you could use 8 (SN30) or 4 (SN20) tensor parallel weight mode.