Compose complex operations with parallel patterns
SambaFlow explicitly supports a comprehensive set of PyTorch operators. In addition, you can use parallel patterns operators, which act as modular building blocks for more complex operators, to create operators that are not currently explicitly supported in SambaFlow.
The parallel patterns operators capture parallelizable computation on both dense and sparse data collections. This enables exploitation and high utilization of the underlying platform while allowing a diverse set of models to be easily written.
Available operators
The available parallel pattern operators are:
sn_gather and sn_scatter are memory access patterns. They are loosely based on XLA’s version of Gather: XLA Gather and Scatter: XLA Scatter.
sn_gather
sn_gather is used to extract individual elements, single-dimension slices, or multi-dimensional slices from a lookup table. A single sn_gather operation can extract multiple individual elements, single-dimension slices, or multi-dimension slices. These multiple extractions are called batches.
sn_gather is defined as:
sn_gather(input_tensor: Tensor,
start_indices: Tensor,
gather_dims: List[int],
gather_lengths: List[int]) -> Tensor-
input_tensoris the lookup table from which values are being extracted. -
start_indicescontains 1 index per gather dimension per batch corresponding to a location in the lookup table where the extraction begins. -
gather_dimsis a list of integers denoting which dimensions to gather along. Dimensions which appear ingather_dimshave a corresponding index instart_indices(per batch). Dimensions which do NOT appear ingather_dimsare gathered in their entirety. -
gather_lengthscorresponds 1 to 1 withgather_dimsand specifies how many elements are extracted along each gather dimension. A gather length can range from 1 to size(dim).
For example,
input_tensor (3x3) = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
start_indices (2x1) = [[1],[0]] # 2 "batches", 1 gather dim
gather_dims = {0} # Gather along dimension 0
gather_lengths = {2} # Gather 2 elements (per batch) along dimension 0. Dim 1 is gathered in its entirety
output = sn_gather(input_tensor, start_indices, gather_dims, gather_lengths)
output (2x2x3) === [[[4,5,6],[7,8,9]],[[1,2,3],[4,5,6]]] # 2 batchs of 2x3 slices
The leading dimension(s) of sn_gather correspond to the "batches" and match the leading dimension(s) of start_indices.
|
sn_scatter
sn_scatter is used to insert/override individual elements, single-dimension slices, or multi-dimensional slices into a destination tensor. A single sn_scatter operation can extract multiple individual elements, single-dimension slices, or multi-dimension slices. These multiple extractions are called batches.
sn_scatter is defined as:
sn_scatter(operand: Tensor,
update: Tensor,
start_indices: Tensor,
scatter_dims: List[int],
rmw_op: str = "kUpdate",
unique_indices: bool = False) -> Tensor-
operandis the destination tensor which values will be scattered into. This tensor will contain initial values. -
updateis the tensor containing the values being scattered.start_indicescontains 1 index per scatter dimension per batch corresponding to a location in the destination tensor where the scatter will begin. This is identical to thestart_indicestensor insn_gather -
scatter_dimsis a list of integers denoting which dimensions to scatter along. Dimensions which appear inscatter_dimshave a corresponding index instart_indices(per batch). Dimensions which do NOT appear inscatter_dimsare scattered in their entirety. -
rmw_opis an opcode which specifies an (optional) arithmetic operation to be performed during the scatter between the value being scattered and the value already present in the destination. Supported RMW ops are ["kUpdate", "kAdd", "kMin", "kMax", "kMul"].-
"kUpdate" is the default and overwrites the value at the destination.
-
"kAdd" adds the update value and the value at the destination before inserting into the destination.
-
"kMul" multiplies the update value and the value at the destination before inserting into the destination.
-
"kMin" and "kMax" compare the update value with the value at the destination and only insert the update value if it is less than the destination value or greater than the destination value respectively.
-
-
unique indicesis an optimization flag. If you know that every location in the destination will be scattered to a maximum of 1 time, then you can setunique_indicesto true, for a possible performance increase.unique_indicesdefaults tofalse.
Consider the following example. Note that there is no scatter_length argument. The scatter length is implicitly defined in the update tensor’s shape.
destination (3x3) = [[0, 0 ,0],[0, 0, 0],[0, 0, 0]]
update (2x2x3) = [[[1, 2, 3],[4, 5, 6]],[[7, 8, 9],[10, 11, 12]]] # 2 batches of 2x3
indices (2x1) = [[1],[0]] # Leading dimension matches leading dimension of update
scatter_dims = {0}
rmw_op = "kAdd"
output = sn_scatter(destination, update, indices, scatter_dims, rmw_op)-
First the 2x3 batch [[1,2,3],[4,5,6]] is scattered along dim 0 at index 1. These 6 values are added to the 6 values already present in the destination tensor. In this example, the initial values of the destination are all 0s.
-
After first 2x3 batch: [0,0,0],[1,2,3],[4,5,6]
-
Then the second 2x3 batch, [[7,8,9],[10,11,12]] is scattered along dim 0 starting at index 0. These values are added to the existing values in the destination, resulting in the final output tensor:
output (3x3) = [[7, 8, 9],[11, 13, 15],[4, 5, 6]] # Same size as provided desination tensor
sn_gather and sn_scatter are more generalized than torch.gather and torch.scatter and support wider range of gather and scatter dimensions.
|
torch.gather and torch.scatter implicitly infer indices for the non-gather and non-scatter dimensions based on their position in the indices tensor. Note how the indices in dims 1 and 2 are inferred (j,k).
torch_gather_out[i][j][k] = input[index[i][j][k]][j][k] # if dim == 0In contrast, you use sn_gather as follows:
sn_gather_out[i][0][0][0] = input[index[i][0]][index[i][1]][index[i][2]]sn_zipmapreduce
sn_zipmapreduce is used for element-wise computation followed by an optional reduction. The name zipmapreduce is a combination of zipmap and reduce where:
-
The zipmap corresponds to the element-wise computations
-
The reduce corresponds to a reduction along one or more dimensions
sn_zipmapreduce takes a lambda expression that contains an arbitrary number of zip and map operations as an argument and takes an optional argument to specify a reduction.
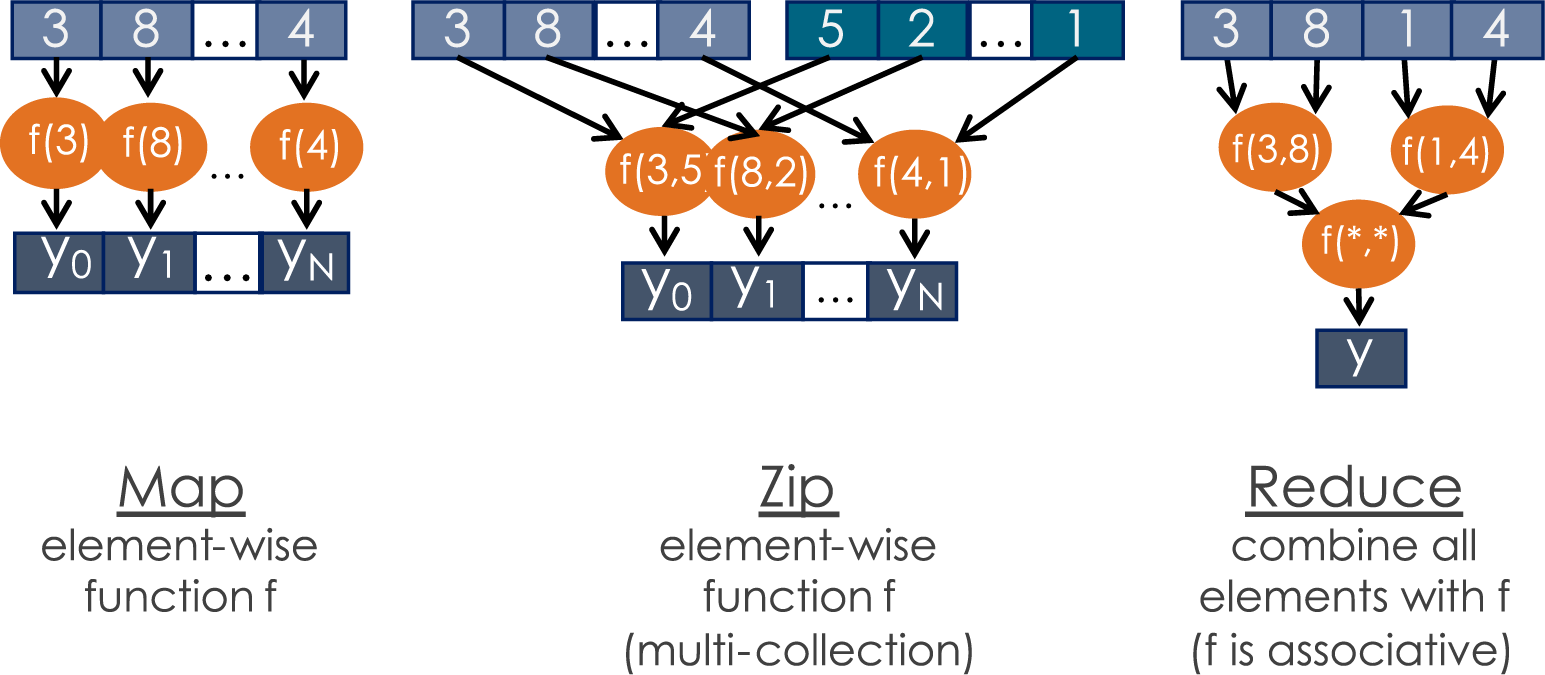
Parallel pattern examples
Examples of sn_zipmapreduce usage to form a more complex composed operation:
DiagonalFill Example
# Fills upper triangle (excluding main diagonal) of 4D tensor with fill_value
def forward(self, x: SambaTensor) -> SambaTensor:
def diagonal_fill(attrs, x):
dim_l = sn_iteridx(dim=2, attrs=attrs, dtype=idx_type)
dim_r = sn_iteridx(dim=3, attrs=attrs, dtype=idx_type)
condition = torch.ge(dim_l, dim_r)
result = sn_select(condition, x, sn_imm(fill_value, torch.float32))
return result
return `sn_zipmapreduce`(diagonal_fill, [x])RotaryEmbedding Example
def forward(self, x: SambaTensor, x_roll: SambaTensor, y: SambaTensor, y_roll: SambaTensor) -> SambaTensor:
def compute_complex(attrs, x, x_roll, y, y_roll):
even_out = x * y - x_roll * y_roll
odd_out = x_roll * y + x * y_roll
i = sn_iteridx(dim=3, attrs=attrs)
one = sn_imm(1, get_int_type(get_int_or_float_bit_width(x.dtype)))
is_odd = torch.bitwise_and(i, one)
out = sn_select(is_odd, odd_out, even_out)
return out
return sn_zipmapreduce(compute_complex, [x, x_roll, y, y_roll])