SambaFlow learning map
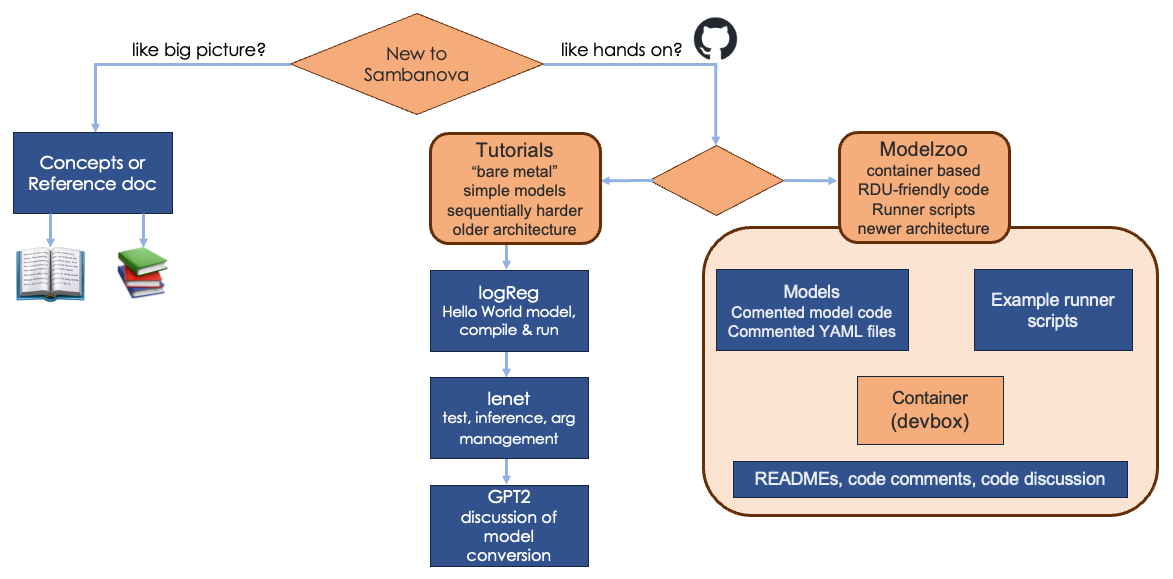
Welcome! This doc page is a learning map for users new to SambaNova. It helps you see the big picture and find the information you need quickly. Here’s an overview:
Get the big picture: Architecture and concepts
Many of us learn best by understanding the big picture first — having a look at a map before exploring unknown territory. The doc set includes several pages that help you get oriented (or dig deep after initial exploration with the code).
-
Architecture and workflows. Explains how the SambaFlow components fits into the SambaNova hardware and software stack and includes links to resources.
-
SambaFlow compiler overview. Discusses the compiler stack and explains how model compilation works and includes links to reference materials and other resources.
-
White paper. SambaNova Accelerated Computing with a Reconfigurable Dataflow Architecture
 .
Discusses the architecture in some detail. Not required reading, but might be of interest.
.
Discusses the architecture in some detail. Not required reading, but might be of interest.
Learn by doing: Tutorials and Model Zoo
Many of us learn best by doing. You can start with the new Model Zoo offering or choose from our older (and simpler) tutorials.
Model Zoo
The Model Zoo initiative includes a new public GitHub repo with these components:
-
The code for several open source LLMs that have been customized to run efficiently on RDU.
-
A set of example apps for compile/train and compile/inference workflows.
-
For each model, a commented YAML configuration file that allows you to run the model using the example apps (with minor modifications)
See the Model Zoo documentation and the SambaNova Model Zoo ![]() GitHub repo for details.
GitHub repo for details.
The typical workflow in the Model Zoo scenario is like this:
-
Clone the public GitHub repo.
-
Select a model, and download a checkpoint for that model from Hugging Face.
-
Prepare the data that you want to use to fine tune the model.
-
Use the training example app with the
compile`option to compile the model and generate a PEF file. Both the example app and the customized model were downloaded from the SambaNova public GitHub. -
Use the training example app with the train
optionto fine-tune the model. You pass in the generated PEF file and the data you prepared for fine tuning. -
After you’ve completed training the model with your custom data, you can use the resulting custom checkpoint for generation (inference).
Tutorials: GitHub and doc
Choose one of our tutorials to come up to speed quickly. For tutorials, you clone the repo and compile and train directly on your SambaNova system. The tutorials use an earlier architecture, so some of the aspects of running on RDU are not shown in the code example. On the other hand, the tutorials are simple and include extensive code discussions. There’s special emphasis on comparing code on RDU with code on CPU.
-
Find tutorial code and a README with instructions in our sambanova/tutorials
public GitHub repo. -
For each tutorial, explore the code discussion in this doc set, which has a special focus on how code for running on RDU is different from code in other environments.
-
The learning map above points to some additional materials. For example, even if you’re trying out a simple model, the API Reference
is useful.
The tutorials in this doc set use different code than tutorials included in
/opt/sambaflow/apps. Tutorial examples have been updated and streamlined.
|
| Tutorial | Description | Code and README | Code discussion |
|---|---|---|---|
Hello SambaFlow (logreg) |
Learn how to compile and and run training. The tutorial code downloads the dataset. |
||
Intermediate (lenet) |
Step through a complete machine learning workflow. Includes data preparation, compilation and training run, and compilation and inference run. |
||
Conversion 101 |
Learn about converting a PyTorch model to run on RDU looking at a simple CNN model. Includes two solutions: One uses an integrated loss function, another uses an external loss function. |
Basics in Convert a simple model to SambaFlow |
Examine functions and changes Examine model code with external loss function |
Transformers on RDU |
Use a pretrained Hugging Face GPT-2 model on RDU. The tutorial discusses data preparation, compilation and training and compilation and inference. The code is in two separate files. |
Code elements of the training program |
Data preparation, SambaNova Runtime, and SambaTune
The following resources in this doc set or elsewhere might help you learn more:
-
Data preparation scripts. We have a public GitHub repository
with two scripts for pretraining data preparation, pipeline.pyanddata_prep.py. -
SambaNova Runtime documentation. Information on logs, fault management, and other lower-level procedures.
-
SambaTune documentation. SambaNova tool for performance optimization (advanced).