SambaFlow developer documentation
SambaFlow™ developer documentation includes release notes, quickstart, tutorials, and the Python API reference.
What’s new in 1.21
The focus of this release is SambaNova Model Zoo.
-
The Model Zoo public GitHub repo is a set of custom source code, example apps, and other code and script for running models on RDU. README files and some other documentation help you get started.
-
SambaNova customers can download and deploy a container image with SambaFlow and other prerequisite software and use it with Model Zoo code and scripts.
See the Model Zoo Release Notes for details.
Concepts
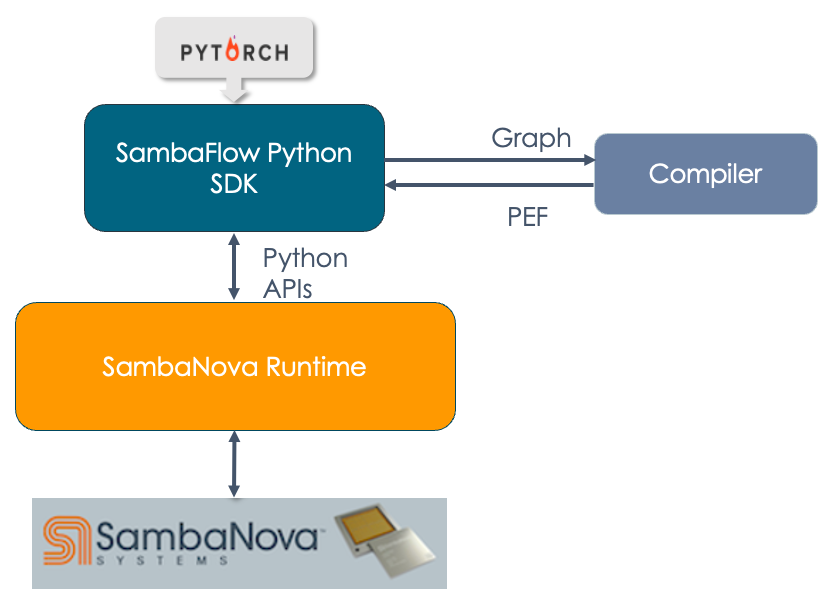
-
Architecture and workflows. Learn how SambaFlow fits into the SambaNova hardware and software stack, and about the typical compile and run workflow.
-
Compilation overview. Explore the different layers of the compiler stack and explains what happens at each layer.
-
Compiler optimization modes. Learn about compiler optimization modes that give you control over operator fusion.
Model Zoo and Tutorials
SambaNova offers two public GitHub repos that allows customers to experiment with models. The SambaNova Tutorials offer a sequential way of learning about SambaNova models. In the modelzoo repo, you find models that use our newer architecture.
Model Zoo
With Model Zoo, you compile and run the model in a container that you get from SambaNova customer support. We expect that you’ll learn primarily from code comments and README files in the modelzoo repo itself, but we also have some overview material in this doc set.
-
Model Zoo architecture and workflows. Explores the Model Zoo architecture and workflows.
-
Get started with Model Zoo. Gets you started. You learn about the architecture and about the steps for running a modified Llama model on RDU hardware.
-
Model Zoo best practices. Learn from the expert how you can avoid problems and optimize your runs.
-
Model Zoo troubleshooting. Troubleshooting information for Model Zoo users.
Tutorials
SambaNova offers two public GitHub repos that allows customers to experiment with models. The SambaNova Tutorials offer a sequential way of learning about SambaNova models. In contrast to the container-based Model Zoo models, the Tutorial models run directly on the operating system.
-
SambaFlow learning map. Overview of all tutorials and where to find instructions, tutorial files, and code discussion.
-
Hello SambaFlow! Learn how to compile and run your first model (duplicate of the README on GitHub) and explore the code discussion to help you create your own models.
-
Intermediate tutorial. Build on Hello SambaFlow! and learn about data download and running inference in Compilation, training, and inference (duplicate of the README on GitHub). The code discussion is in Examine LeNet model code.
-
Model conversion 101. Learn what’s required to run a PyTorch model on RDU from the detailed discussion of code examples in Convert existing models to SambaFlow.
-
Transformers on RDU. Use a pretrained Hugging Face model on RDU. The tutorial discusses data preparation, compile and training run, and running inference in Compile, fine-tune, and perform inference with a Hugging Face GPT model and discusses the model code in Code elements of the training program and Code elements of the inference program.
-
Troubleshooting SambaFlow Tutorials. Resolve issues with tutorial complation and training. We’re planning on updating this topic over time.
How-to guides
In our How-to Guides you learn about some specific areas such as data parallel with SambaNova.
-
How to use data parallel mode. Learn about improving performance by compiling and running in data parallel mode.
-
How to use tensor parallel mode (Beta). Learn how tensor parallel mode enables compiling a model to run more efficently on RDUs.
-
Compile with mixed precision (Beta). Learn about compiling with mixed precision, which combines the use of different numerical formats (such as FP32 and BF16). Benefits include a reduced memory footprint and speed up of large neural network workloads.
-
Compose complex operations with parallel patterns. Learn how to use existing parallel pattern operators to create operators that aren’t currently supported on RDU.
-
Use multigraph to partition models. Learn how to use the multigraph feature when your model consists of separate PyTorch modules and you want to have fine-grained control on when to run them.
-
Use sntilestat for performance analysis. Learn how to use the
sntilestatutility interactively to learn where your model spends time, and how to use the .json and .csv files the tool generates. -
Use a supported or custom learning rate scheduler Learn which schedulers are supported out of the box, and how to use a custom scheduler instead.
Reference
-
SambaNova messages and logs. Learn about messages to stdout and about the location of different logs.
-
Arguments for compile. Reference to commonly used compiler arguments. Includes descriptions and examples.
-
Operator fusion rule yaml syntax. Reference to the operator fusion rule yaml syntax. These yaml files are used in conjunction with o1 compiler mode.
-
Hyperparameter reference. Reference to supported hyperparameters. supported PyTorch operators. Includes links to the API Reference.
Tips and tricks
-
Uncorrectable Error Replay (Beta). Learn how the new UE error replay feature works and how to use it.
-
Use Python virtual environments. Learn how to use the virtual environments that are included with SambaFlow example applications.
-
Use LayerNorm instead of BatchNorm. Learn how to convert a model from BatchNorm to LayerNorm.
-
Backpropagation best practices. Learn how to use token ids to customize which tokens a model learns to generate, and which tokens a model attends to, but does not learn to generate. Understand how to perform output gradient initialization.
-
Use a supported or custom learning rate scheduler. Learn how to use supported and custom learning rate schedulers.
-
Best practices for hardware transition. If you’re migrating to SN30 hardware, the best practices help you understand changes to your models you might want to make.
Other materials
-
Data preparation scripts. We have a public GitHub repository
 with two scripts for pretraining data creation,
with two scripts for pretraining data creation, pipeline.pyanddata_prep.py. -
SambaNova Runtime documentation. Information on logs, fault management, and other lower-level procedures.