Model conversion overview
This doc page gives an overview of changes you make when you prepare your existing PyTorch model on RDL. You can learn more in our conversion examples.
-
Model conversion 101 explains the basics and discusses model code in Examine functions and changes and Examine model code with external loss function.
-
Use pretrained models on RDU illustrates how to use a pretrained Hugging Face model to perform inference on RDU. We use GPT-2 because compilation happens quickly. Code discussion is in Code elements of the training program and Code elements of the inference program.
The basics
This section discusses some basics that help you understand what working in a SambaNova environment is all about.
SambaTensor and torch.Tensor
SambaTensor ![]() is a wrapper around
is a wrapper around torch.Tensor with additional SambaNova capabilities.
A SambaTensor has:
-
A unique name for interfacing with the RDU
-
An optional, user-defined
batch_dimfor optimization -
Methods to transfer the tensor between the RDU and system host
In all other ways, you can treat a SambaTensor like a torch.Tensor. For example:
-
tensor3 = tensor1 + tensor2 -
tensor2 = tensor1.reshape(-1, 5)
To take advantage of SambaTensor capabilities, you call:
-
samba.from_torch_tensor(torch.Tensor, name="example_name")
Function overrides
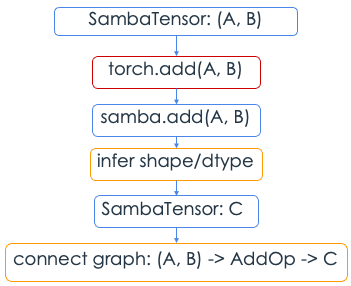
You don’t have to explicitly define functions to manipulate SambaTensor.
If you pass a SambaTensor to a torch function, SambaFlow overrides the torch method
and calls the equivalent SambaFlow method.
-
If you pass a torch tensor to
torch.add(), the torch method is called. -
If you pass a
SambaTensortotorch.add(), SambaFlow callssamba.add().
Tracing, compilation, and dummy tensors
Tracing refers to the conversion of a dynamic graph to a static graph.
The purpose of tracing is to walk through the PyTorch computation graph
and map it onto the RDU. As part of the process, we override the torch functions
(e.g., Conv2d) with the SambaFlow implementation.
During tracing, the compiler applies optimization techniques that greatly improve training time. In a SambaNova environment, tracing walks through the model with "dummy" tensors as part of compilation. These dummy tensors (which you define as part of your model code) must have the same shape as the input tensors to your model, but don’t have to contain any meaningful data.
Compilation
Tracing happens automatically during compilation. See SambaFlow compiler overview if you’re interested in how the compiler works.
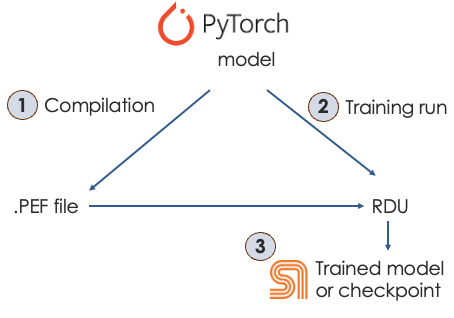
The compiler performs tracing during the forward pass. Note that the compiler does not
support control flow within a model. Conditional statements do not become a part of
the computational graph on RDU; only those branches that evaluated to True are preserved.
Compilation generates a PEF file: a binary file that contains the full details of the compiled model that can be deployed onto an RDU. You then pass the PEF file to the training function.
It’s possible to explicitly call the trace_graph() utility function (see samba.utils.trace_graph ![]() for details).
for details).
This is done after the model is compiled.
RDU and CPU
If a specific operation is not supported on RDU, the parameters needed for that operation
should be transferred to CPU, perform the operation, then sync it back to RDU with to_rdu.
| Write your model to stay on RDU as much as possible. Transferring data between RDU and CPU has a significant performance hit. |
Model porting workflows
When you prepare your PyTorch model to run on SambaNova hardware, you can leave most of the existing model code intact. The Convert a simple model to SambaFlow doc page illustrates this. Here’s an overview of the pieces.
Data preparation
SambaNova has two data preparation scripts in our public GitHub repository ![]() .
.
-
The
generative_data_prep/data_prep/data_prep.pyscript tokenizes a single jsonline or text file, packs it into fixed length sequences and converts it to HDF5 format. -
The
generative_data_prep/data_prep/pipeline.pyscript facilitates end-to-end data preparation for training machine learning models. This script:-
Takes a single jsonline or text file as input
-
Shuffles the input and splits it into multiple
train/dev/testfiles -
Calls
generative_data_prep/data_prep/data_prep.pyon all the splits to tokenize the text, pack it into fixed length sequences, and convert to HDF5 format.
-
Prepare the model for compilation
Each SambaNova model must call the samba.session.compile() function.
During compilation, you pass in your PyTorch model and dummy input tensors,
and the compiler generates a PEF file. If you start with a working PyTorch model,
only fairly minimal changes are required.
In your code:
-
Convert model parameters to Samba format using samba.from_torch_model_

-
Convert each torch tensor to SambaTensor using samba.from_torch_tensor_
-
Convert the model using one of two functions:
-
Either the
compile()function (SambaSession.compile) -
Or the
common_app_driver()utility function. This function is deprecated and a replacement is in progress.
-
-
For either function, specify the following required arguments:
-
The model.
-
The dummy input tensors (as described earlier).
-
The optimizer (SambaFlow supports
AdamWandSGD).
-
-
Specify arguments that the user can specify when calling the compilation function.
-
The arguments specified in Compiler argument reference are always supported.
-
Most models also support a set of model-specific arguments used for compilation, e.g., batch size and number of epochs.
-
| For small POC models, you compile only once and use the generated PEF file for training and for inference. For all other models, we recommend a separate compilation for inference to make your model run more efficiently. |
Prepare models to run training
Each SambaNova model must include a training function. If you start with a working PyTorch model, only fairly minimal changes are required, as the existing training loop can be used in SambaFlow.
-
Make all the changes required for model compilation.
-
Create a training function around the training loop. See Train the model with train() for a full explanation of a training loop.
-
Call the training function. Here’s a simple example:
# Running, or training, a model must be explicitly carried out if args.command == "run": # Trace the graph utils.trace_graph(model, inputs, optim, pef=args.pef, mapping=args.mapping) # Within the user defined train function, call: samba.session.run train(args, model) -
The training function takes as input the
model(converted to SambaFlow) and other data required to run the model. Ensure that therunfunction takes the input tensors, output tensors, and section types. During training, all 3 section types are required. During inference, onlyforwardis required. -
The call to
samba.session.run()allows the model to run on RDU. It takes as input:-
The true tensors (not the dummy tensors).
-
A pointer to where the output tensors will be stored (these are generated during graph tracing).
-
A list of names of sections to be run.
outputs = samba.session.run(input_tensors=inputs, output_tensors=traced_outputs, section_types= ['fwd', 'bckwd', 'opt'])
-
-
If your model has hyperparameters that are adjustable during training, specify them via
hyperparam_dict, a dictionary of key value pairs that is updated during the run. Examples might include:-
Learning rate (lr)
-
Weight decay (weight_decay)
-
SGD momentum (momentum)
-
Dropout rate (p)
-
See Hyperparameter reference for details.
Prepare models to run inference
Running inference consists of these tasks:
-
Compile for inference. To run inference, you must first compile the model for inference by calling the
compilefunction with the--inferenceargument. The result of compilation is a PEF that is optimized for inference. -
Run inference. To run inference with your trained model, you also pass the
--inferenceargument and:-
The inference PEF file
-
A checkpoint (an inference model isn’t trained in this case, so needs to be instantiated with weights)
-
A dataset for inference
-
After you’ve run inference, you can check how your model performed. See Compilation, training, and inference and Code elements of the inference program for examples.