Use a supported or custom learning rate scheduler
The learning rate and the loss function both affect the training of machine learning models.
-
The learning rate directly affects how the model’s parameters are updated during the optimization process
-
Parameter updates impact the value of the loss function.
For example, during each iteration of the training process, the model computes the gradient of the loss function with respect to its parameters.
-
The gradient indicates the direction in which the parameters should be adjusted to minimize the loss.
-
The learning rate determines the step size taken in the direction of the gradient.
SambaFlow supports most of the popular learning rate schedulers out of the box. This document discusses the supported schedulers, which work for most use cases, and briefly explores using a custom scheduler.
Supported schedulers
By default, SambaFlow supports the following schedulers:
-
cosine_schedule_with_warmup— Adjusts the learning rate according to the--warmup_stepsand--max_stepsarguments following a plot. -
polynomial_decay_schedule_with_warmup— Looks similar to the cosine decay, but uses a linear decay instead of cosine decay (the “polynomial” part of the name is misleading; decay is always linear). -
fixed_lr— Fixed LR means there is no learning rate schedule at all, and the learning rate remains the what’s specified in--learning_ratethroughout training.
Parameters that affect learning rate and schedulers
Here’s a list of the command line arguments which control learning rate schedule.
Not all models support all arguments. Run python <model> run --help to see which arguments your model supports.
|
-
--learning_rate. Peak learning rate when employing a schedule with warmup, or the flat learning rate when usingfixed_lr. -
--lr_schedule. One ofcosine_schedule_with_warmup,polynomial_decay_schedule_with_warmup, orfixed_lr -
--warmup_steps. If you are using one of the schedulers with warmup, number of steps over which to linearly increase the learning rate up to the value specified by--learning_rate. Set this to 0 to specify no warmup at all. -
--max_steps. the number of steps over which to decay the learning rate. This will also be the number of training steps that the model will finish training at. To set your LR scheduler to decay over a different number of steps than you actually run training for, specify both--max_stepsand--steps_this_run. Use--max_stepsto control the learning rate and--steps_this_runto control the number of actual training steps taken. -
--end_lr_ratio. the fraction of the peak LR to end decay at. The default ratio is different forcosine_schedule_with_warmupwhich ends at 0.1x the peak rate, andpolynomial_decay_schedule_with_warmup, which ends at 0.0
Using a custom scheduler
If you specifically want to experiment with the LR schedule as an independent variable, it likely makes sense to edit learning_rate_schedule.py and then import their own learning rate. For example for our Transformers model, you’d import your learning rate into gpt2_task.py.
Custom scheduler example
The examples below use a plus sign (+) in front of a code line that was added, and a minus sign (-) in front of a code line that was removed.
|
Suppose you want to add a scheduler with that decays the learning rate by 0.5 every 100 steps.
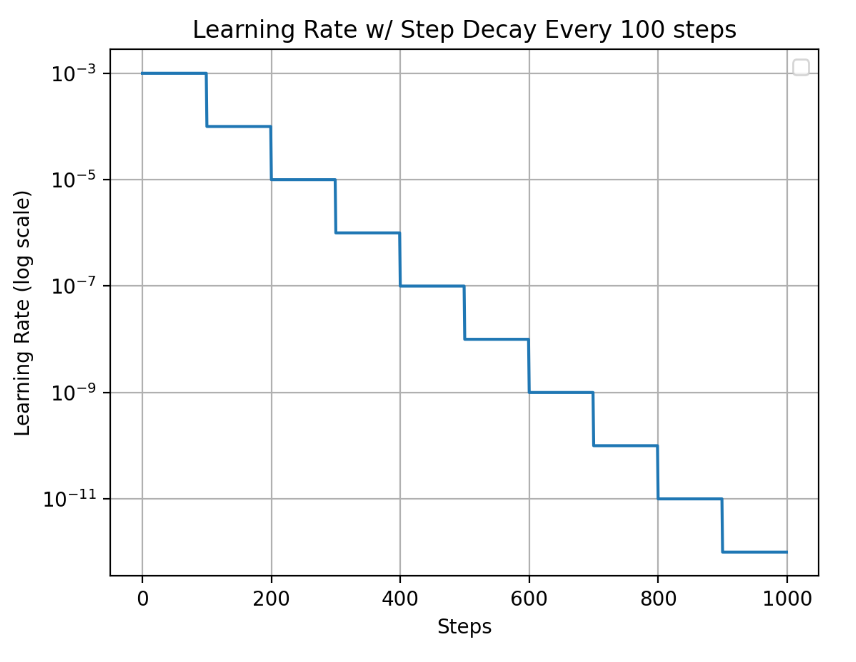
Using the PyTorch LambdaLR class, you can implement this scheduler like this:
from torch.optim.lr_scheduler import LambdaLR
def get_step_schedule(optimizer, decay_steps, last_epoch=-1, gamma=0.5):
def lr_lambda(current_step):
num_cycles = int(math.floor(current_step / decay_steps))
return gamma ** num_cycles
return LambdaLR(optimizer, lr_lambda, last_epoch)-
Add this function to
tasks/utils/learning_rate_schedule.pyundersambaflow/apps/nlp/transformers_on_rdu.Now, make changes to the model code at
tasks/lm_tasks/gpt2_task.py -
Import the new scheduler function.
-from tasks.utils.learning_rate_schedule import get_cosine_schedule_with_warmup +from tasks.utils.learning_rate_schedule import get_cosine_schedule_with_warmup, get_step_schedule -
Add the function to the
get_lr_schedulermethod:elif args.lr_schedule == "cosine_schedule_with_warmup": end_lr_ratio = None if args.end_lr_ratio is None: end_lr_ratio = 0.1 else: end_lr_ratio = args.end_lr_ratio return get_cosine_schedule_with_warmup(optimizer=optimizer, num_warmup_steps=args,warmup_steps, num_training_steps=args,max_steps, num_cycles=0.5, last_epoch=-1, end_ratio=end_lr_ratio) + elif args.lr_schedule == 'step_schedule': + return get_step_schedule(optimizer=optimizer, decay_steps=args.decay_steps, gamma=args.decay_gamma, last_epoch=-1) -
Add the arguments you want to
GPT2TrainArguments.interpolate: Optional[bool] = field(default=False, metadata={"help": "Run interpolation"}) + decay_steps: Optional[int] = field(default=100, metadata={"help": "Period of steps over which to decay the learning rate when using step_schedule as the learning rate schedule"}) + decay_gamma: Optional[float] = field(default=0.5, metadata={"help": "Constant by which to decay the learning rate when using step_schedule as the learning rate schedule"}) -
Specify your custom learning rate by adding
--lr_schedule step_schedule --decay_steps 100 --decay_gamma 0.5in your training command.
In the example above, the StepLR schedule is already implemented by PyTorch, so you can directly import it in gpt2_task.py without needing to write the code yourself. The following example steps should have the same results as the example above:
-
Update the top-level imports.
+ from torch.optim.lr_scheduler import StepLR -
Add the imports to the
get_lr_schedulermethod:elif args.lr_schedule == "cosine_schedule_with_warmup": end_lr_ratio = None if args.end_lr_ratio is None: end_lr_ratio = 0.1 else: end_lr_ratio = args.end_lr_ratio return get_cosine_schedule_with_warmup(optimizer=optimizer, num_warmup_steps=args,warmup_steps, num_training_steps=args,max_steps, num_cycles=0.5, last_epoch=-1, end_ratio=end_lr_ratio) + elif args.lr_schedule == 'step_schedule': + return StepLR(optimizer=optimizer, step_size=args.decay_steps, gamma=args.decay_gamma, last_epoch=-1) -
Add the arguments you want to
GPT2TrainArguments:interpolate: Optional[bool] = field(default=False, metadata={"help": "Run interpolation"}) + decay_steps: Optional[int] = field(default=100, metadata={"help": "Period of steps over which to decay the learning rate when using step_schedule as the learning rate schedule"}) + decay_gamma: Optional[float] = field(default=0.5, metadata={"help": "Constant by which to decay the learning rate when using step_schedule as the learning rate schedule"})
Learn more
In our model conversion documentation, we explain how to use a custom loss function here.