Architecture and workflows
The SambaFlow™ software stack runs on DataScale® hardware. You can run models on this software stack in several ways:
-
To get started, use the tutorials available from the SambaNova tutorials repo. You can also examine and compile and run models included in
opt/sambaflow/appson your DataScale host. -
To progress, use one of the models available in the SambaNova modelzoo repo. You run Model Zoo models in a DevBox container that includes all prerequisite software. The model source code, which been customized for RDU, is available in a public GitHub repo, which also includes example apps. You can compile a model, and can then run inference (text generation) and fine-tune the model with custom data. To fine tune, you download a checkpoint for the same model (Hugging Face format), prepare your dataset, and compile and train the model.
In this doc page, you learn about the different components of the software stack, the compile/train and compile/generate cycles, and the command-line arguments.
SambaNova Stack
It’s useful to understand the different components of the SambaNova hardware and software stack and how they interact with each other. For example, SambaFlow developers might find it useful to investigate what’s going on in the SambaNova Runtime component.
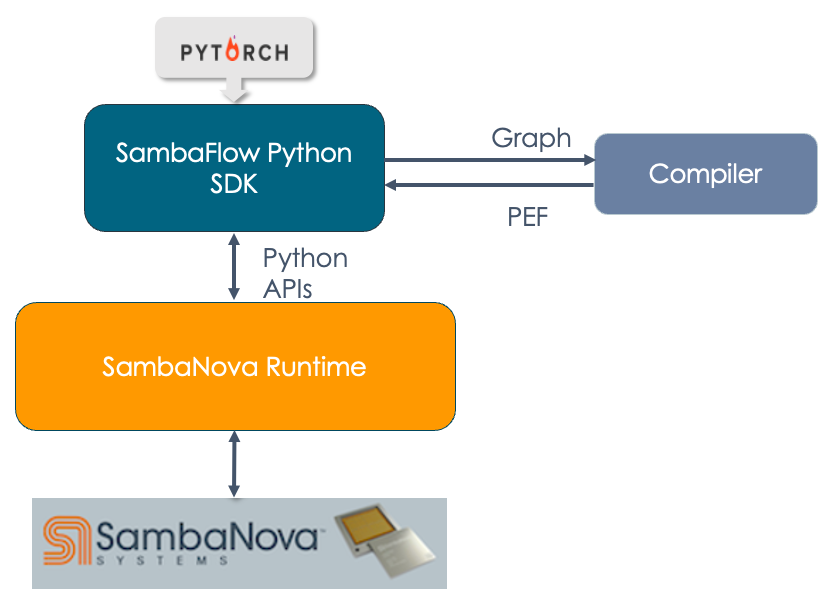
-
SambaNova Reconfigurable Dataflow Unit™ (RDU) is a processor that provides native dataflow processing. It has a tiled architecture that consists of a network of reconfigurable functional units. See the white paper SambaNova Accelerated Computing with a Reconfigurable Dataflow Architecture
 .
. -
SambaNova Systems DataScale is a complete rack-level computing system. Each DataScale system configuration consists of one or more DataScale nodes, integrated networking, and a management infrastructure in a standards-compliant data center rack.
-
SambaNova Runtime. The SambaNova Runtime component loads code and data onto the RDUs and manages the return of result data. System administrators can perform configuration, fault management, troubleshooting, etc. See the SambaNova Runtime documentation for details.
-
SambaFlow Python SDK. The SambaFlow Python SDK serves as our frontend for compiling and running models on SambaNova hardware.
-
SambaFlow models. We offer models in several places.
-
Starter models are included on the SambaNova host at
/opt/sambaflow/apps/and are targeted towards the new user. -
SambaFlow models in our sambanova/tutorials
GitHub repo allow you to examine the Python code and then perform compilation, training, and inference runs. See SambaFlow tutorials. -
Model Zoo, available from the public modelzoo repo includes model source code that’s been customized to work well on RDU, and scripts for running them. You run the models in a Devbox container. You can use Model Zoo in conjunction with checkpoints in Hugging Face format (and a corresponding config.json) to fine tune the model with your data.
-
Workflows
When you develop for RDU hardware, you start with model code, optional checkpoints, and fine-tuning data. You end with a trained model that might for example, responds to prompt data.
Data preparation workflow
It’s possible to start by training from scratch with large data sets, but it usually makes sense to work with an existing checkpoint and fine-tune that checkpoint with your own data. In both cases, your data needs to be in a format that SambaFlow can work with.
| Data preparation is a much-discussed topic in AI. This doc page doesn’t go into data preparation details but focuses instead on the format of the data, not the content. |
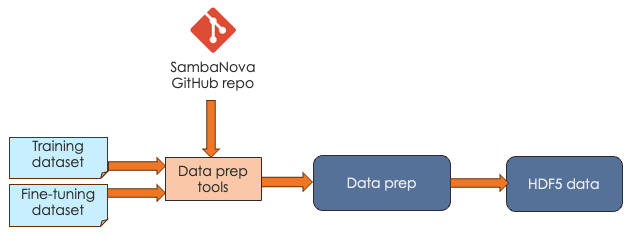
SambaNova expects that you pass in your data as HDF5 files. Our public generative_data_prep repo ![]() includes scripts and documentation for converting plain text or jsonline format files to HDF5 format.
includes scripts and documentation for converting plain text or jsonline format files to HDF5 format.
Training workflow
The goal of the training workflow is to generate a a checkpoint that you can then use in a generation workflow.
-
First you compile for training and generate a PEF file. The PEF file defines the dataflow graph for the SambaNova hardware.
-
Then you run training with the data of your choice and pass in the PEF file.
| With the small tutorial models, you can complete a training run. For the much larger Model Zoo models, we recommend that you download a checkpoint from Hugging Face and run training with your model source, the checkpoint, and your custom data instead. |
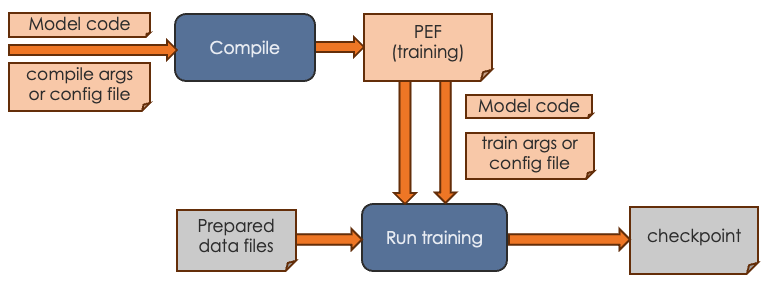
For the training workflow, you proceed as follows:
-
Complete data preparation, discussed in Data preparation workflow
-
Perform compilation by running the compilation command, passing in the model code and arguments.
-
If you’re using the container-based Model Zoo solution, you specify most arguments in a YAML config file and specify only a few on the command line.
-
If you’re using one of the tutorial examples, you specify all arguments on the command line. See Compiler argument reference.
The output of the compilation step is a PEF file, which defines how the model is run on SambaNova hardware. You cannot edit a PEF file.
-
-
Perform training by running the training command, passing in the PEF file, the configuration info for training, and the prepared data files.
-
If you’re using the container-based Model Zoo solution, you specify most arguments in a YAML config file and specify only a few on the command line. Because Model Zoo models are large models, you typically pass in a check point that you download from Hugging Face. Training a model from scratch without a checkpoint takes a long time. See the examples README for a walkthrough example with Llama2.
-
If you’re using one of the tutorial examples, you specify all arguments on the command line. Run the training command with
--helpto see all arguments.As part of a training run, information about loss and accuracy are logged to stdout.
-
-
Examine the loss and accuracy information, which is logged to stdout as part of a training run.
-
If you’re running a Model Zoo model, observe the output. If you see that loss is decreasing, your PEF is valid. You can then perform fine tuning with your own data and a Hugging Face checkpoint.
-
If you’re running a tutorial example, you can run training to completion. The output is a checkpoint file that you can use for fine tuning.
-
Fine-tuning workflow
The most common use case for SambaNova customers is to start with an existing model, generate a PEF file, fine-tune the model with custom data, and then use the model for generative inference. The workflow looks like this:
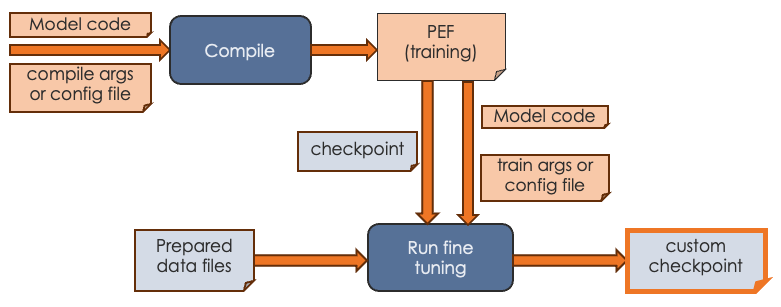
During fine tuning, you create a version of the model that’s been trained with your organization’s data.
-
Before you start fine tuning, ensure that you have the custom data in the correct format, as discussed in Data preparation workflow.
-
Start a training run and pass in:
-
A PEF file that was the output of compilation.
-
A checkpoint. For a Model Zoo model, use a publicly available Hugging Face checkpoint. For a tutorial model, you can use a checkpoint generated by a training run.
-
The configuration parameters, either on the command line or, for Model Zoo models, in a configuration file.
-
-
Output of the fine tuning run is a model checkpoint that has been fine tuned with your custom data. You can then pass in that checkpoint when you runfine- inference (generation).
Inference (generation) run
The final step is running generative inference. In this step, you send prompt data to the trained model and the model responds to the prompt or performs summarization, identification, etc. The actual tasks your model can perform depends on the model itself.
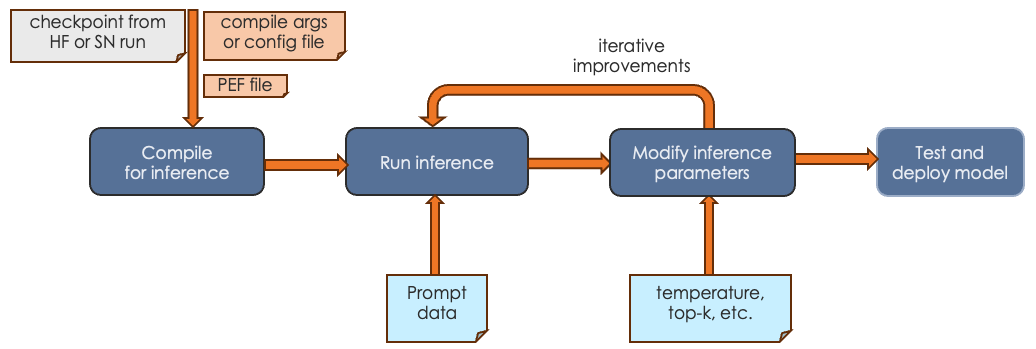
-
In most cases, you first compile an inference PEF. Compilation for inference consists only of the forward pass.
-
You run inference, passing in a checkpoint and prompt data or other input.
-
You can experiment with inference parameters, such as temperature, topk, etc. Some parameters require a recompile, others do not.
-
When you’re satisfied with the results, you can deploy the tested model.
See Run and verify inference for an example discussion.
Command-line arguments
SambaNova initially used a workflow where users passed all configuration arguments in on the command line. With our more recent Model Zoo initiative, we are using a Pydantic and Hydra infrastructure. Most arguments are specified in a YAML configuration file. A few arguments, such as the name of the PEF file, are specified on the command line.
Command-line arguments for Model Zoo models
For Model Zoo models, we have greatly simplified argument management for the developer and argument usage for the person who uses the model. A combination of Pydantic and Hydra make this possible.
-
Model developers are encouraged to become familiar with the Pydantic and Hydra infrastructure to reap the benefits of streamlined argument management.
-
Model users will notice that the scripts for running the model have a different syntax than before. For example, here’s how you might invoke generation:
/opt/sambanova/bin/python $HOME/modelzoo/modelzoo/examples/text_generation/run_rdu.py \
command=compile \
model.cache_dir=/opt/sambanova/modelbox/checkpoints \
model.batch_size=1 \
+samba_compile.target_runtime_version=1.3.7 \
+samba_compile.output_folder=/opt/out \
+samba_compile.pef_name=llama2_7b_inferCommand-line arguments for other models
For tutorial models and for models at /opt/sambaflow, each model supports different command-line arguments. To see all arguments, run the model with the task (compile or run) and --help, for example, app.py compile --help.
Compilation
-
All models support the shared arguments that are documented in Arguments to compile.
-
You can generate a PEF for inference by specifying the
--inferencecompile flag. By default, we compile for training, which includes a forward, backward, and optimization pass. Inference compilation is only a forward pass. -
All models support a shared set of experimental arguments, usually used during debugging when working with SambaNova Support. To include these arguments in the help output, run
app.py compile --debug --help. -
Additionally, each model has a set of model-specific arguments that are defined in the app code.