SambaFlow compiler overview
When you compile a PyTorch model with SambaFlow, the model is processed at several layers. This document explains what happens at each layer, and discusses arguments you can use to affect processing at each layer.
When you want to run a model on SambaNova hardware, the typical workflow always includes a compilation step.

This doc page gives background information about the SambaFlow compiler stack and optimization modes. You learn about the architecture, so you can then optimize compilating using compiler arguments.
Compiler stack layers
At the highest level, the compiler consists of a few key components – the graph compiler, the kernel compiler, and the kernel library.
Here’s what happens when you compile and run a model:
-
The PyTorch model, via SambaNova Python API, goes through the graph compiler to transform the original model into a series of RDU kernel dataflow graphs.
-
The kernel compiler is then responsible for transforming each kernel dataflow graph into a bitfile, and compiling these bitfiles together into an executable (PEF file).
-
The user invokes the
runcommand to perform a training or inference run, and passes in the PEF file as input.
The following illustration shows the compiler stack on the left and the runtime stack on the right.
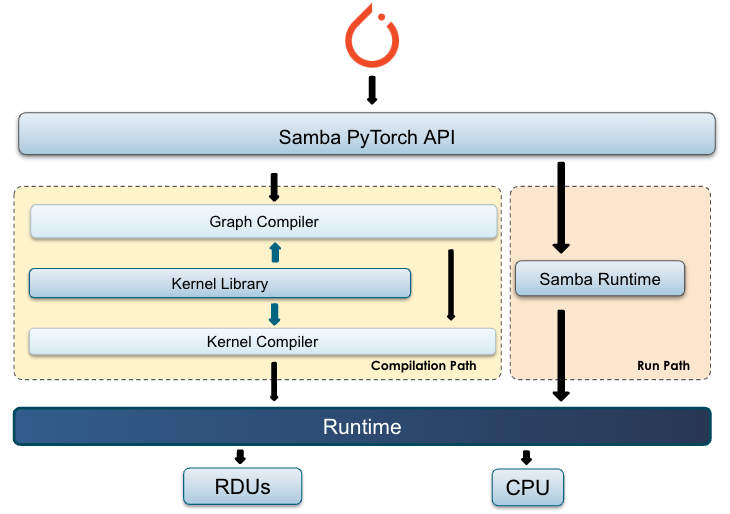
Here’s an overview of the components:
-
Samba. A Python-based software layer responsible for model graph tracing, invoking the SambaFlow compiler, and orchestrating model execution.
-
Graph compiler. Responsible for model-level graph transformation and optimizations. Transforms an ML model graph into a graph that consists of RDU kernels and execution schedules.
-
Kernel compiler. Responsible for transforming RDU kernel graphs into a PEF file. A PEF file is then used as the input to the training step.
-
Kernel library. A set of ML operator kernels (e.g. Gemm) that supports both the graph compiler and the kernel compiler. The library includes PyTorch operators that are optimized for RDU.
How model compilation works
During model compilation, the SambaFlow components go through several steps, in sequence.
-
When you compile for training (the default) the process includes all steps.
-
When you compile for inference (by passing in the
--inferenceargument), the compiler does not compute the gradient of the loss function automatically.
In the following explanation, each node is a PyTorch operator (Gemm, Relu, etc).
1 |
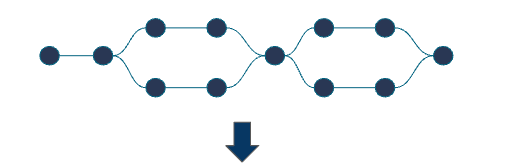
|
Samba traces the model and constructs its model graph. Each node in the diagram on the left is a PyTorch operator. |
2 |
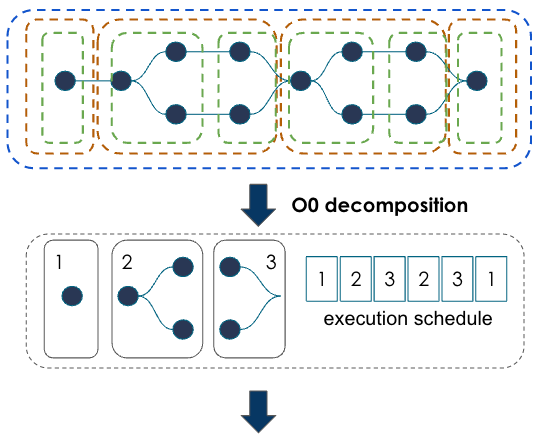
|
During compilation, the graph compiler performs graph decomposition. Users can control how the compiler breaks up the graph into subgraphs with the following parameters:
See Compiler argument reference and Compiler optimization modes for details. |
3 |
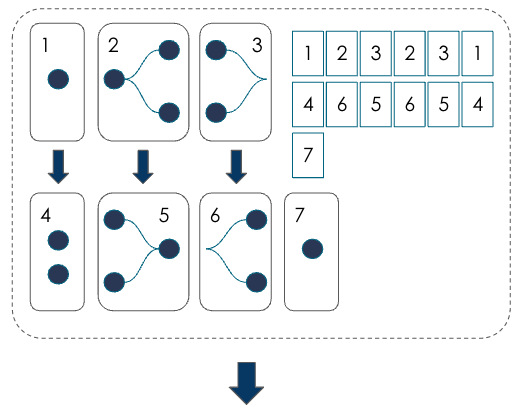
|
To support training, the compiler computes the gradient of the loss function automatically using autograd and adds an optimizer function. |
4 |
|
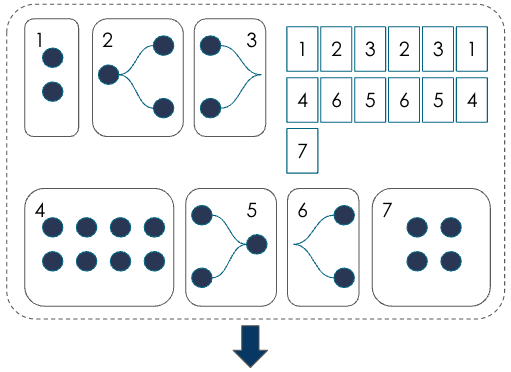
Next, the graph compiler performs graph optimizations including tensor transformations and optimizations, operator parallelizations, and peephole optimizations. |
5 |
|
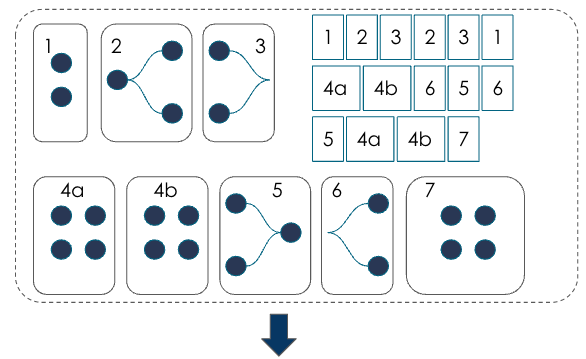
During graph mapping, each function is mapped into 1 or more sections (the compiler lowers each function into 1 or more section). One section is the basic unit of compute that runs on the RDU at a time. |
6 |
|
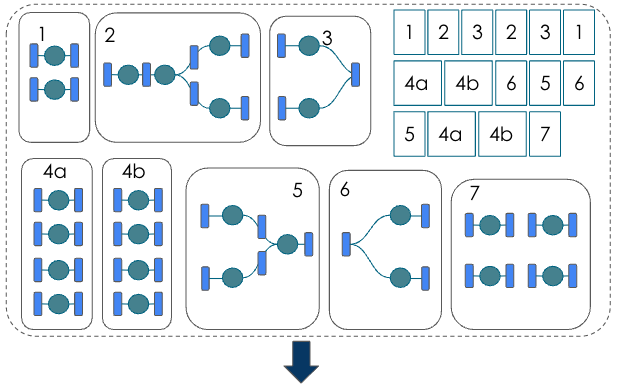
During graph lowering, the graph compiler lowers from mathematical operators to kernel operators. As part of this process, the compiler performs dataflow pipeline construction and optimizations.
|
7 |
|
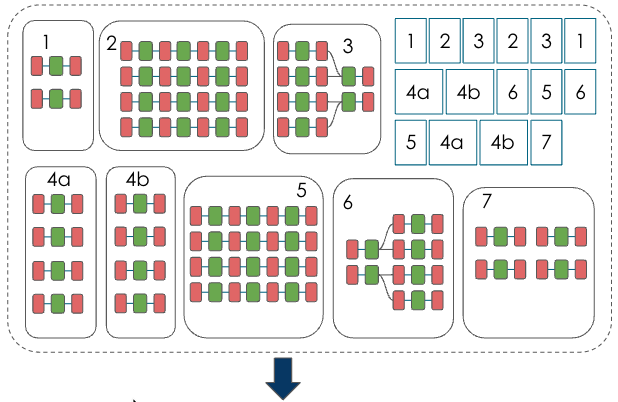
Next, the kernel compiler maps the PCU/PMU graphs onto the physical PCU/PMU instances, and generates bitfiles and the PEF file. The PEF file can then be used as the input to the first training run.
|
|
||


Learn more!
-
See Compiler argument reference for a reference to compiler arguments.
-
See Compiler optimization modes to learn about the o0 and o1 optimization modes.