Dynamic batching
SambaStudio SN40L users can create endpoints that use dynamic batching of requests to the same model, which provides improved throughput and performance. Dynamic batching is accomplished by utilizing a local request queue, which manages the incoming requests.
Local request queue
SambaStudio uses a local request queue to dynamically switch and manage incoming requests. Based on the current queue length, SambaStudio will dynamically adjust the batch sizes for a model, ensuring optimal performance and resource utilization.
For example, many of the listed models below support batch sizes of 1, 4, 8, and 16. The batch size will be selected by the platform and dynamically switched based on the number of requests waiting in the local request queue. The input requests are distributed to each instance via load balancing, with the requests dispatched to each instance placed in the local request queue. The following conditions apply when the RDUs are available to start a new inference run:
-
If there is one request in the local request queue, batch size 1 will be selected and executed to minimize the latency.
-
If there are seven requests in the local request queue, batch size 8 will be selected and executed (with padding if the number of requests is less than eight) to maximize the throughput.
-
If there are 50 requests in the local request queue, the largest batch size of 16 will be selected and executed repeatedly. Then a smaller batch size will be selected to execute the remaining small batch of requests (with padding if the number of requests is less than eight) to maximize the throughput.
Dynamic batching models
The Composition of Experts (CoE) models listed below support dynamic batching in SambaStudio. Please view the SambaStudio model card of each model for detailed information.
-
Samba-1 Turbo Llama 3 70B 8192 dynamic batching
-
Samba-1 Turbo Llama 3 70B 4096 dynamic batching
-
Samba-1 Turbo Llama 3 8B 8192 dynamic batching
-
Samba-1 Turbo Llama 3 8B 4096 dynamic batching
-
Samba-1 Turbo Llama 2 13B 4096 dynamic batching
-
Samba-1 Turbo Llama 2 7B 4096 dynamic batching
-
Samba-1 Turbo Deepseek Coder 6.7B 4096 dynamic batching
-
Samba-1 Turbo Mistral 7B 4096 dynamic batching
Create a dynamic batching CoE endpoint
Follow the steps below to create a CoE endpoint that can use dynamic batching of requests to the same model. After adding your dynamic batching CoE endpoint, adjust the endpoint share settings to share your dynamic batching CoE endpoint with other users and tenants.
|
Due to the large number of checkpoints involved, CoE endpoints can stay in the Setting Up status for 2-3 hours before deploying to Live status. |
-
Create a new project or use an existing one.
-
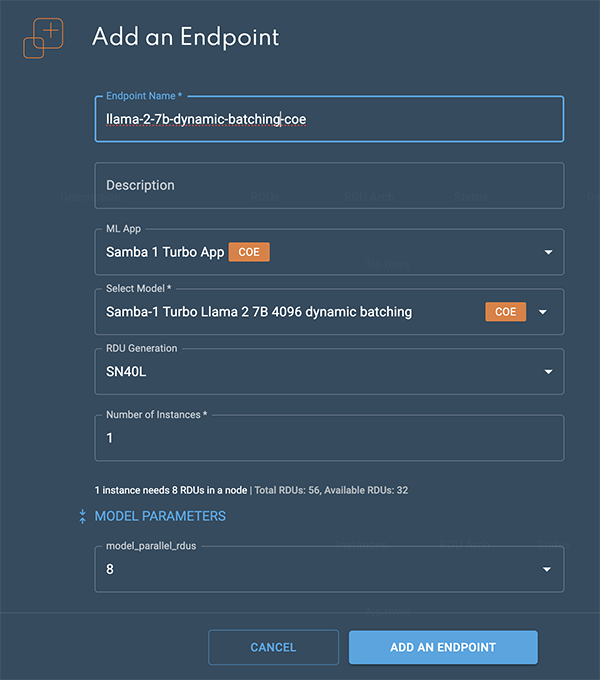
From a project window, click New endpoint. The Add an endpoint window will open.
-
In the Add an endpoint window, enter a name for the endpoint into the Endpoint name field.
-
From the ML App drop-down, select a CoE dynamic batching ML App. A CoE badge indicates a CoE ML App. We selected Samba-1 Turbo App.
-
From the Select model drop-down, choose SambaNova models and select a downloaded dynamic batching CoE model. A CoE badge indicates a CoE model.
-
Select the number of instances to use when creating the endpoint. The information statement displays the required number of RDUs in a single node along with the total number and available number of RDUs in your SambaStudio configuration. In our example, our dynamic batching CoE model requires one RDU in a node for each instance. Increasing the number of instances will increase the RDU requirements.
-
Expand Model Parameters to view additional parameters.
-
The model_parallel_rdus field designates the number of RDUs used to run in parallel when creating the endpoint.
-
-
Click Add an endpoint to queue the endpoint for deployment.
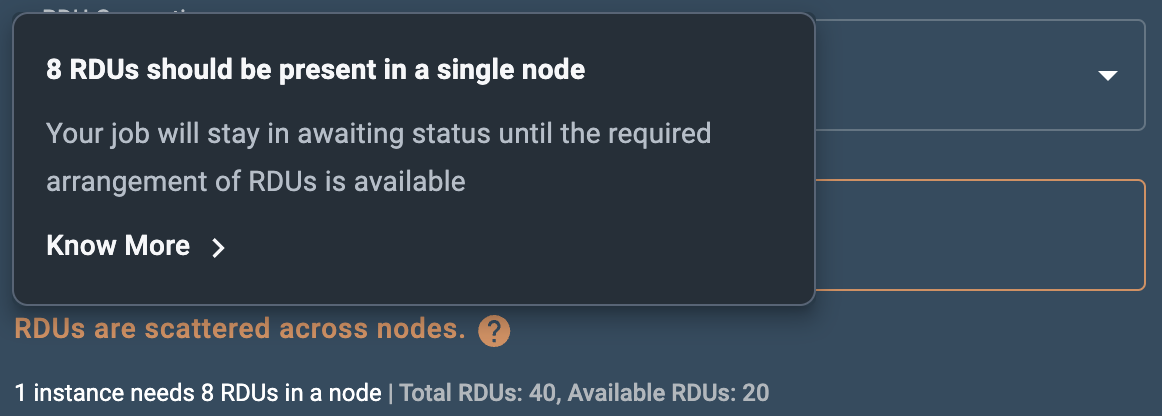
Insufficient RDUs in a single node
When creating a new endpoint, if the required number of RDUs are not available in a single node, you will receive a warning message stating that your endpoint will be in Awaiting RDU status until the RDUs become available in a single node. Contact your administrator for more information on RDU configurations specific to your SambaStudio platform.
Interact with your deployed dynamic batching endpoint
Once your dynamic batching endpoint has been deployed, you can interact with it as demonstrated in the example curl requests below. See the Online generative inference section of the API document for request format details.
Interact with a CoE dynamic batching endpoint
Please note the following regarding our example curl request for a CoE dynamic batching endpoint:
-
Insert your prompt into
USERPROMPT. -
The example below makes a call to the Meta-Llama-3-8B-Instruct expert via the property
"select_expert":{"type":"str","value":"Meta-Llama-3-8B-Instruct"}.
curl -X POST \
-H 'Content-Type: application/json' \
-H 'key: <your-endpoint-key>' \
--data '{"instance":"{\"conversation_id\":\"sambaverse-conversation-id\",\"messages\":[{\"message_id\":0,\"role\":\"user\",\"content\":\"USERPROMPT\"}]}","params":{"do_sample":{"type":"bool","value":"false"},"max_tokens_to_generate":{"type":"int","value":"4096"},"process_prompt":{"type":"bool","value":"true"},"repetition_penalty":{"type":"float","value":"1"},"select_expert":{"type":"str","value":"Meta-Llama-3-8B-Instruct"},"temperature":{"type":"float","value":"0.7"},"top_k":{"type":"int","value":"50"},"top_p":{"type":"float","value":"0.95"}}}' 'https://<your-sambastudio-domain>/api/predict/generic/stream/<project-id>/<endpoint-id>'Benchmarking AI Starter Kit
The Benchmarking AI Starter Kit ![]() allows you to evaluate the performance and experiment with different LLM models hosted in SambaStudio, including dynamic batching models.
allows you to evaluate the performance and experiment with different LLM models hosted in SambaStudio, including dynamic batching models.