Use Sambaverse
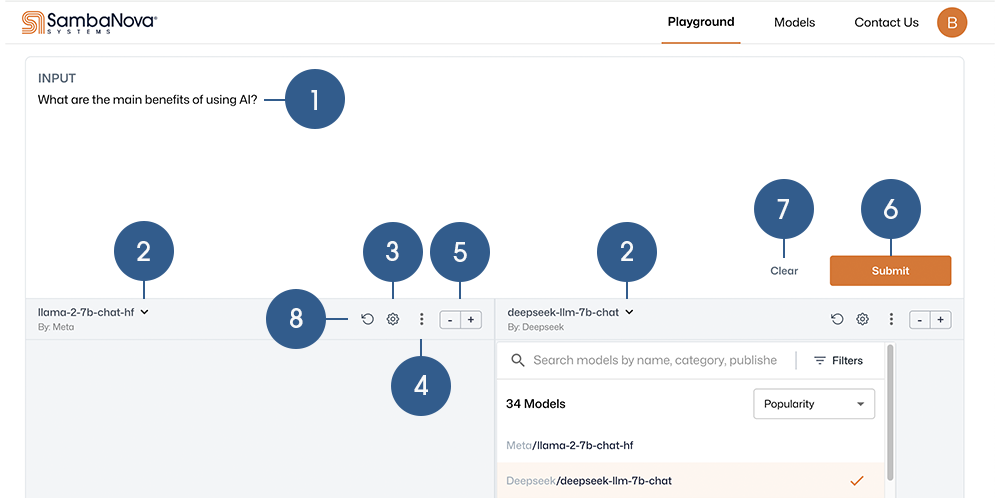
The intuitive interface of Sambaverse allows you to easily experiment with open source models to find the best match for your needs. The sections below provide additional information on using Sambaverse.
Playground
The Playground ![]() allows you to compare and evaluate models using your prompt.
allows you to compare and evaluate models using your prompt.
 Input a prompt for your selected model(s).
Input a prompt for your selected model(s).
 Choose a model to use from the drop-down.
Choose a model to use from the drop-down.
 Adjust the Tuning Parameters to maximize the performance and output of the response.
Adjust the Tuning Parameters to maximize the performance and output of the response.
 Click to access the View Code and Edit System Prompt drop-down.
Click to access the View Code and Edit System Prompt drop-down.
 Add or remove model response panes. Compare responses to your prompt by adding up to six panes.
Add or remove model response panes. Compare responses to your prompt by adding up to six panes.
 Submit your prompt to generate a response from the selected model(s).
Submit your prompt to generate a response from the selected model(s).
 Clear the current prompt from the Input pane.
Clear the current prompt from the Input pane.
 Regenerate a response, using your input and selected model, in the model response pane.
Regenerate a response, using your input and selected model, in the model response pane.
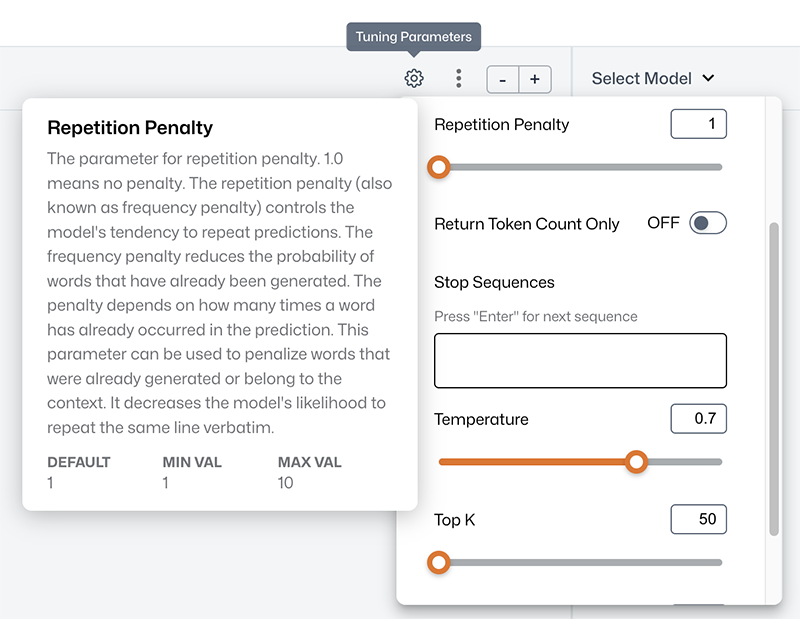
Tuning Parameters
The Playground Tuning Parameters provide additional flexibility and options. Adjusting these parameters allows you to search for the optimal values to maximize the performance and output of the response. Tuning Parameters can be adjusted independently for the selected models in each model response pane of the Playground.
Click the gear icon to view and adjust the parameters for the selected model in the model response pane. Hover over a parameter name to view its definition and values.
The following parameters are available in Sambaverse
- Do sampling
-
Toggles whether to use sampling. If not enabled, greedy decoding is used. When enabled, the platform randomly picks the next word according to its conditional probability distribution. Language generation using sampling does not remain deterministic. If you need to have deterministic results, set this to off, as the model is less likely to generate unexpected or unusual words. Setting it to on allows the model a better chance of generating a high quality response, even with inherent deficiencies. However, this is not desirable in an industrial pipeline as it can lead to more hallucinations and non-determinism.
- Max tokens to generate
-
The maximum number of tokens to generate, ignoring the number of tokens in the prompt. When using max tokens to generate, make sure your total tokens for the prompt plus the requested max tokens to generate are not more than the supported sequence length of the model. You can use this parameter to limit the response to a certain number of tokens. The generation will stop under the following conditions:
-
The model stops generating due to <|endoftext|>.
-
The generation encounters a stop sequence set in the parameters.
-
The generation reaches the limit for max tokens to generate.
-
- Process Prompt
-
When enabled (On), the system prompt and input are internally merged and processed for accurate model calls. When disabled (Off), input prompts are sent unchanged, bypassing any formatting and internal processing.
- Repetition penalty
-
The repetition penalty, also known as frequency penalty, controls the model’s tendency to repeat predictions. A value of 1.0 means no penalty. The repetition penalty reduces the probability of words that have previously been generated. The penalty depends on how many times a word has previously occurred in the prediction. This parameter can be used to penalize words that were previously generated or belong to the context. It decreases the likelihood that the model repeats the same line verbatim.
- Stop sequences
-
Stop sequences are used to make the model stop generating text at a desired point, such as the end of a sentence or a list. It is an optional setting that tells the API when to stop generating tokens. The completion will not contain the stop sequence. If nothing is passed, it defaults to the token <|endoftext|>. This token represents a probable stopping point in the text.
- Temperature
-
The value used to modulate the next token probabilities. As the value decreases, the model becomes more deterministic and repetitive. With a temperature between 0 and 1, the randomness and creativity of the model’s predictions can be controlled. A temperature parameter close to 1 means that the logits are passed through the softmax function without modification. If the temperature is close to 0, the highest probable tokens will become very likely compared to the other tokens: the model becomes more deterministic and will always output the same set of tokens after a given sequence of words.
- Top K
-
The number of highest probability vocabulary tokens to keep for top k filtering. Top k means allowing the model to choose randomly among the top k tokens by their respective probabilities. For example, choosing the top three tokens means setting the top k parameter to a value of 3. Changing the top k parameter sets the size of the shortlist the model samples from as it outputs each token. Setting top k to 1 gives us greedy decoding.
- Top P
-
Top p sampling, sometimes called nucleus sampling, is a technique used to sample possible outcomes of the model. It controls diversity via nucleus sampling as well as the randomness and originality of the model. The top p parameter specifies a sampling threshold during inference time. Top p shortlists the top tokens whose sum of likelihoods does not exceed a certain value. If set to less than 1, only the smallest set of most probable tokens with probabilities that add up to top p or higher are kept for generation.
Prompt engineering
Sambaverse provides a familiar prompt structure that allows you to set context and help define expectations for responses.
Prompt structure
Prompts in Sambaverse include your prompt input, which is enclosed within the inputs along with the system prompt, as shown in the example below. The example below specifies:
-
Input prompt: What are the main benefits of using AI?
-
System prompt: Respond for marketing uses only.
--data '{"inputs":["{\"conversation_id\":\"sambaverse-conversation-id\",\"messages\":[{\"message_id\":0,\"role\":\"system\",\"content\":\"Respond for marketing uses only.\"},{\"message_id\":1,\"role\":\"user\",\"content\":\"What are the main benefits of using AI?\"}]}"]System prompts
System prompts are unique instruction messages used to steer the behavior of models and their resulting outputs.
Task-specific prompt templates
To get optimal responses from a task-specific model, Sambaverse will notify you to use a task-specific prompt template to format your input. Click the right arrow to navigate to the corresponding template. View the task-specific prompt templates and explanations on their usage for each task-specific model.

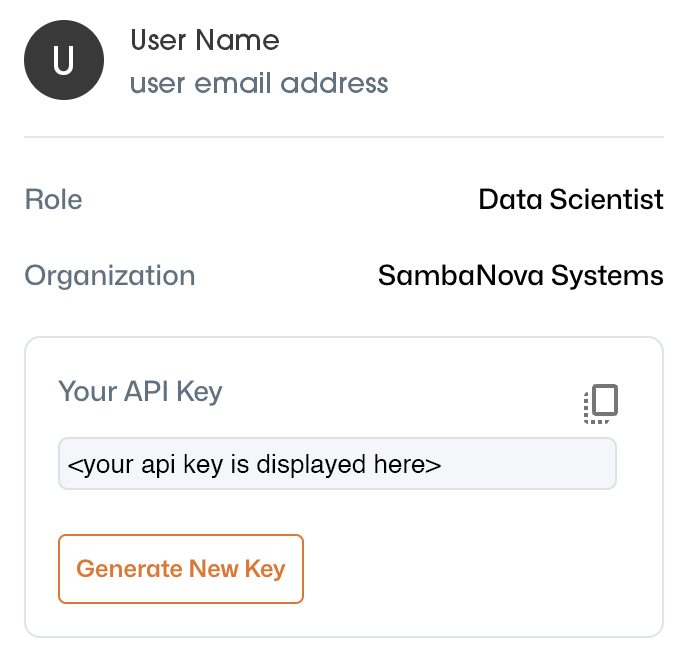
Your API key
Your Sambaverse API key is used to authenticate your requests. You can access and generate your API key from your user profile.
-
Click the orange circle in the top menu bar, next to Contact Us, to view your user profile.
-
Click the copy icon in the Your API Key field to copy your API key to your clipboard.
-
Click Generate New Key to create a new API key. Your new key will display in the Your API Key field.
API reference
Click the kebab (three vertical dots) menu and select View Code to open the cURL Code box. This box allows you to view and copy the curl code generated in each model response pane from the current prompt input. You can then make a request programmatically using the copied code. Click Copy Code to copy the curl code to your clipboard.
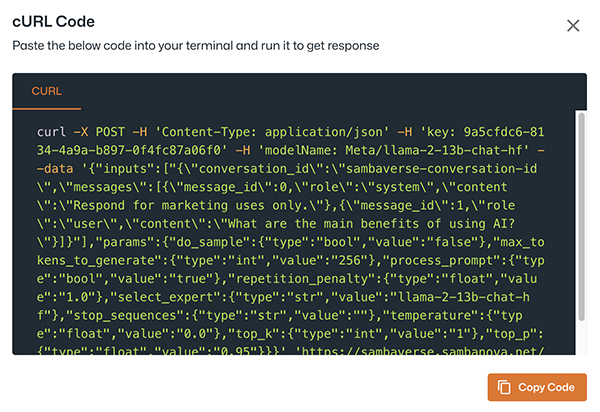
The example curl command below specifies:
-
Input prompt: What are the main benefits of using AI?
-
System prompt: Respond for marketing uses only.
curl -X POST -H 'Content-Type: application/json' -H 'key: <your-api-key>' -H 'modelName: Meta/llama-2-13b-chat-hf' --data '{"inputs":["{\"conversation_id\":\"sambaverse-conversation-id\",\"messages\":[{\"message_id\":0,\"role\":\"system\",\"content\":\"Respond for marketing uses only.\"},{\"message_id\":1,\"role\":\"user\",\"content\":\"What are the main benefits of using AI?\"}]}"],"params":{"do_sample":{"type":"bool","value":"false"},"max_tokens_to_generate":{"type":"int","value":"256"},"process_prompt":{"type":"bool","value":"true"},"repetition_penalty":{"type":"float","value":"1.0"},"select_expert":{"type":"str","value":"llama-2-13b-chat-hf"},"stop_sequences":{"type":"str","value":""},"temperature":{"type":"float","value":"0.0"},"top_k":{"type":"int","value":"1"},"top_p":{"type":"float","value":"0.95"}}}' 'https://sambaverse.sambanova.net/api/predict'curl code structure
Let’s deconstruct the example curl code from above and explain each of its sections.
- Your API key
-
Your API key is used to authenticate your requests. The API key section from the example curl code is shown below.
-H 'key: <your-api-key>'- Model name and publisher
-
The model name and publisher section from the example curl code is shown below. We used the following in the example:
-
Model name: llama-2-13b-chat-hf
-
Publisher: Meta
-
-H 'modelName: Meta/llama-2-13b-chat-hf'- Your prompt input
-
The input prompt that we used in the example curl code is shown below. Note that the prompt input is enclosed within the inputs section along with the system prompt.
--data '{"inputs":["{\"conversation_id\":\"sambaverse-conversation-id\",\"messages\":[{\"message_id\":0,\"role\":\"system\",\"content\":\"Respond for marketing uses only.\"},{\"message_id\":1,\"role\":\"user\",\"content\":\"What are the main benefits of using AI?\"}]}"]- System prompt
-
The system prompt section from the example curl code is shown below.
\"system\",\"content\":\"Respond for marketing uses only.\"}- Parameters
-
The parameters section from the example curl code is shown below. For the select_expert parameter, be sure to include the expert (model). We used llama-2-13b-chat-hf, expressed as "select_expert":{"type":"str","value":"llama-2-13b-chat-hf"}.
"params":{"do_sample":{"type":"bool","value":"false"},"max_tokens_to_generate":{"type":"int","value":"256"},"process_prompt":{"type":"bool","value":"true"},"repetition_penalty":{"type":"float","value":"1.0"},"select_expert":{"type":"str","value":"llama-2-13b-chat-hf"},"stop_sequences":{"type":"str","value":""},"temperature":{"type":"float","value":"0.0"},"top_k":{"type":"int","value":"1"},"top_p":{"type":"float","value":"0.95"}}}'- Endpoint path
-
The path to the endpoint from the example curl code is shown below.
'https://sambaverse.sambanova.net/api/predict'Rate limits
Rate limits determine the number of times Sambaverse can be accessed within a specified time frame. Rate limits are applicable to each individual user based on API keys and only apply to inference calls. We measure rate limits on the number of requests per minute. If you create more requests per minute than are available, the notification message Rate limit exceeded will display in the UI, or you will see a 429 status code error in your curl call.